Model
모델 활용
배포된 API 정보 확인
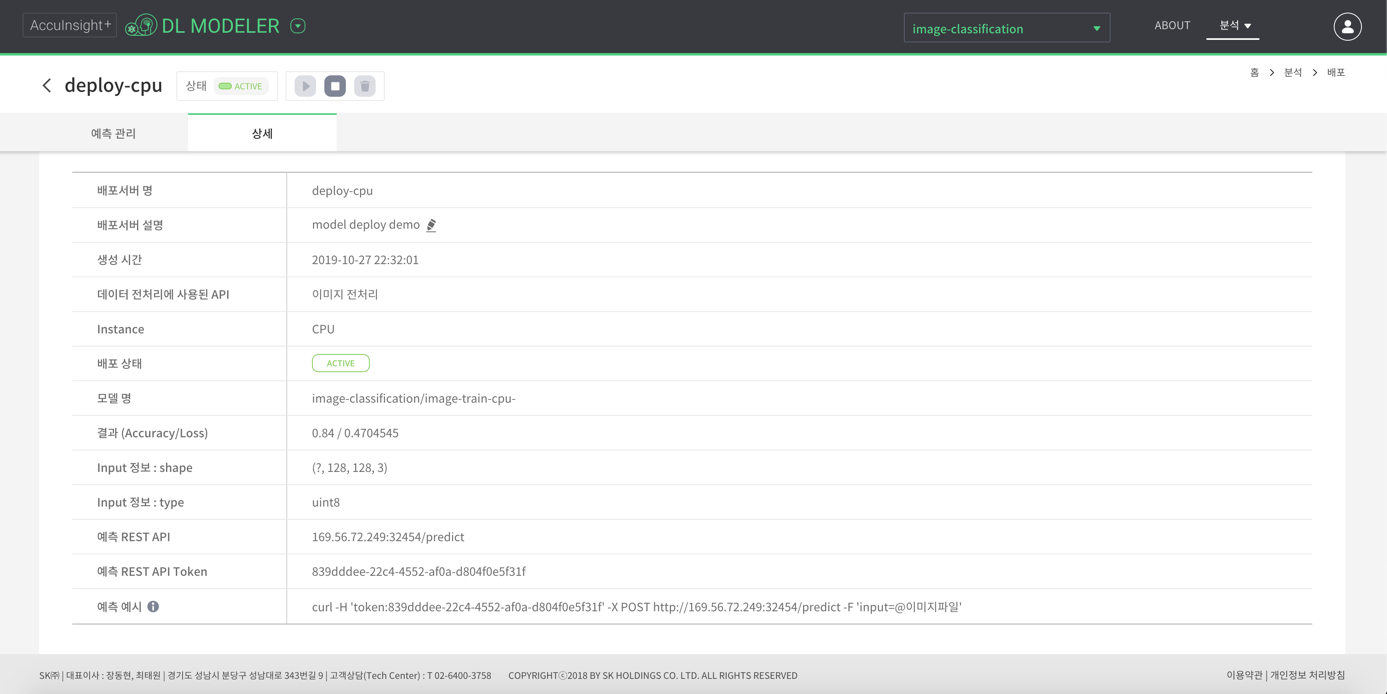
- 배포 상세 탭에서 해당 서버의 상세 정보를 볼 수 있는데, 서버에 API를 던지는 샘플도 여기에 소개된다.
- 배포 서버 설명 중, REST API서버 주소와 인증 토큰은 서버에 api 요청을 보낼 때 사용된다.
- 외부에서 API 활용 demo에서는 방금 만든 toy model 서버가 아닌, 14,034개 전체 데이터로 만든 모델의 API서버에 요청을 보내 분류 데이터를 가져오려고 한다.
파이썬 작업 환경 세팅
- DL Modeler에서 생성한 모델이 실제 분석 업무환경에서 어떻게 활용할 수 있는 지 간단히 알아본다.
- Jupyter notebook에서 이미지 데이터를 가져와 배포한 모델에 API를 보내 분류 결과를 가져오고, 결과를 카테고리로 변환해 함께 출력하는 예시이다
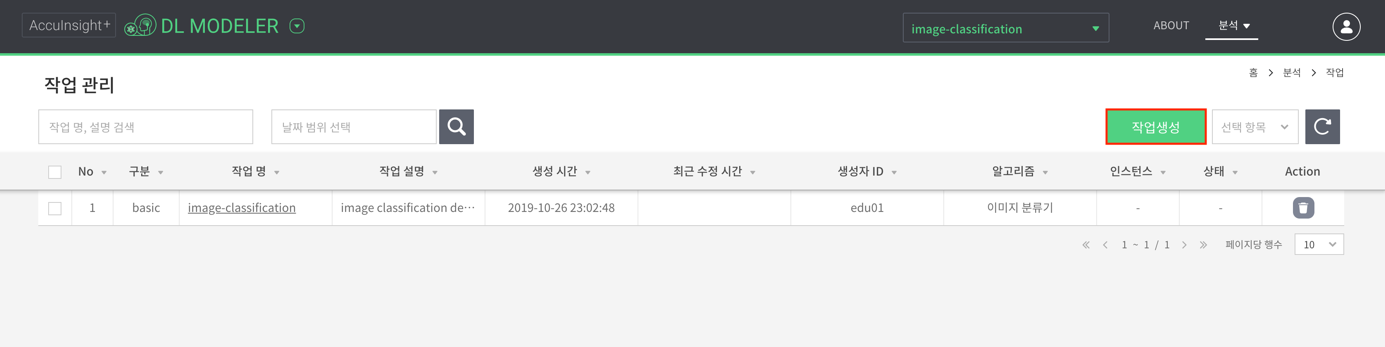
- 작업 생성을 위해 작업 관리 화면으로 이동한다. 우측 상단의 분석 메뉴를 이용하면 된다.
- 작업 관리 화면에서 작업 생성 버튼을 클릭한다.
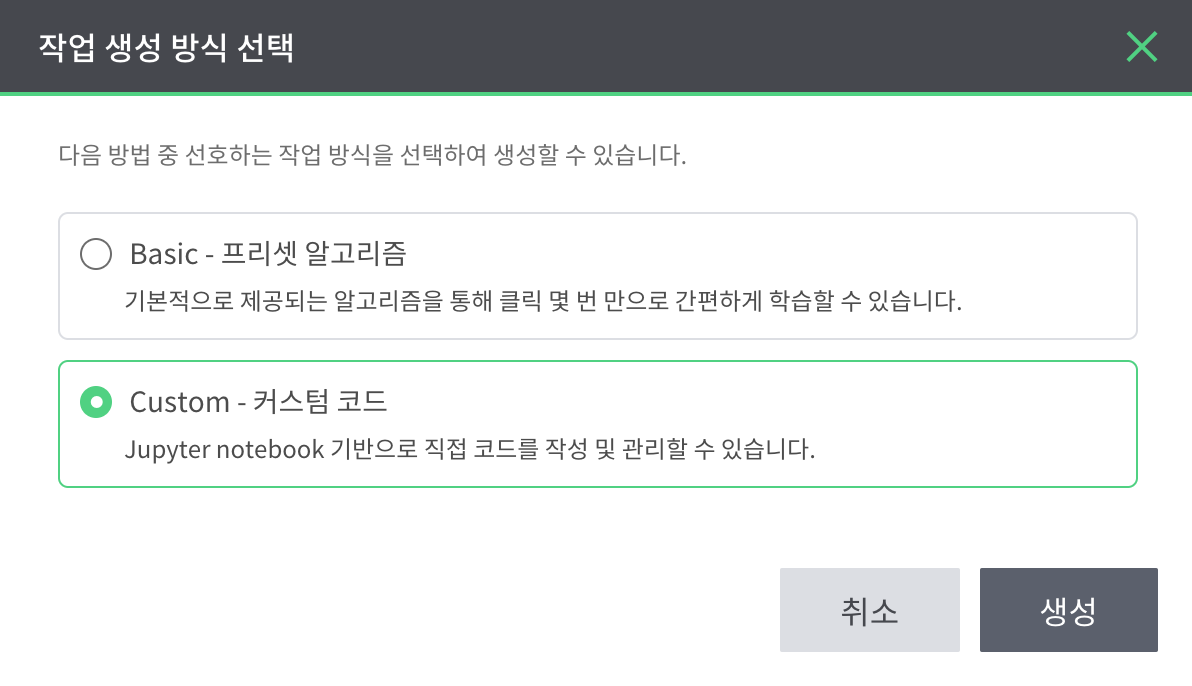
- custom 모드를 선택한 후 생성을 클릭한다.
- custom 작업은 jupyter notebook에 학습 코드를 직접 작성해 학습을 생성하는 기능을 제공한다. 하지만 이번 demo에서는 jupyter notebook만 활용한다.
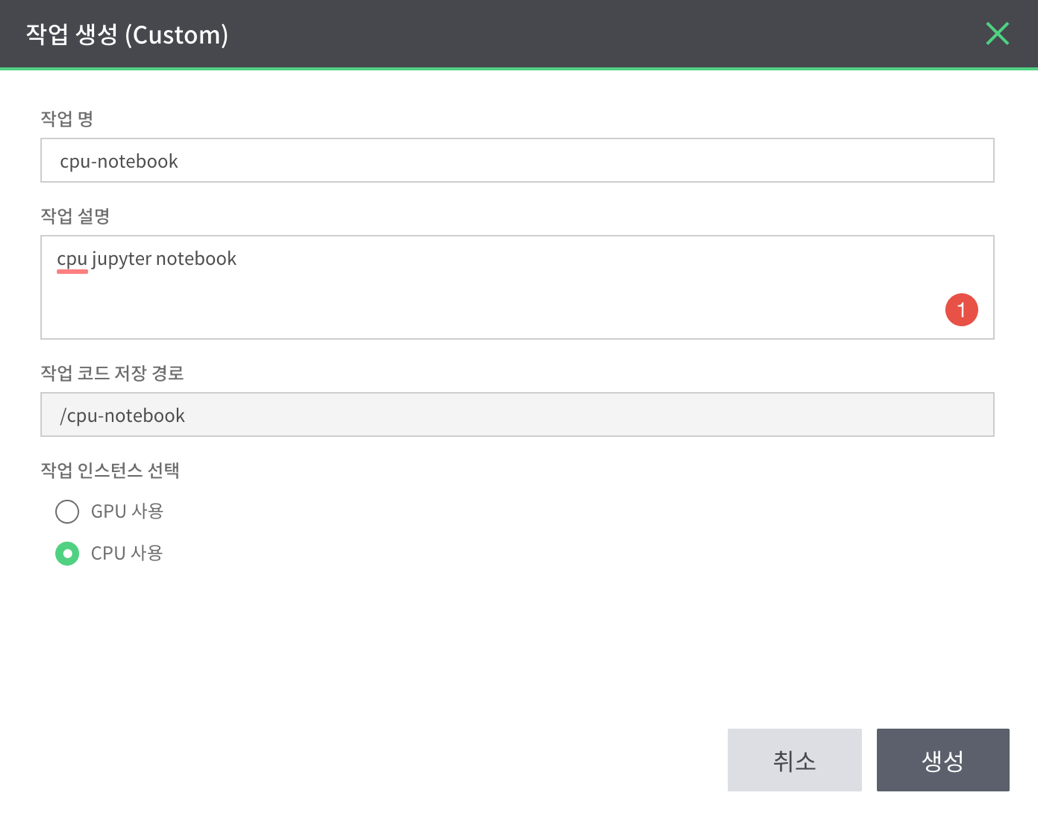
- 생성을 누르면 위와 같은 팝업이 보인다.
- 작업 명과 작업 설명을 입력한다.
- 작업 명: cpu-notebook
- 작업 설명: cpu jupyter notebook
- jupyter notebook에서 별도로 GPU를 사용할 일이 없으므로, 작업 인스턴스는 CPU를 선택한다.
- 생성을 클릭하면 custom 작업이 생성된다.
jupyter notebook으로 예측
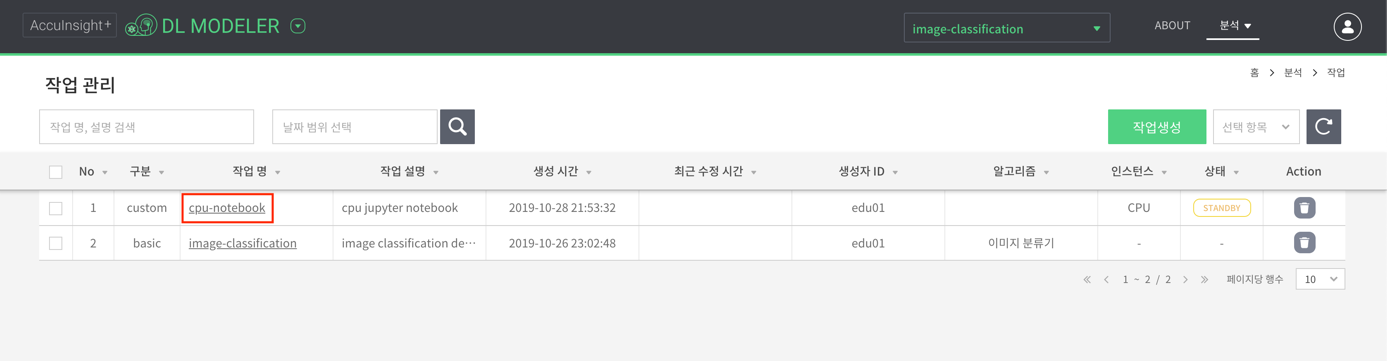
- 생성된 작업 명을 클릭하여 학습 관리 페이지로 진입한다.
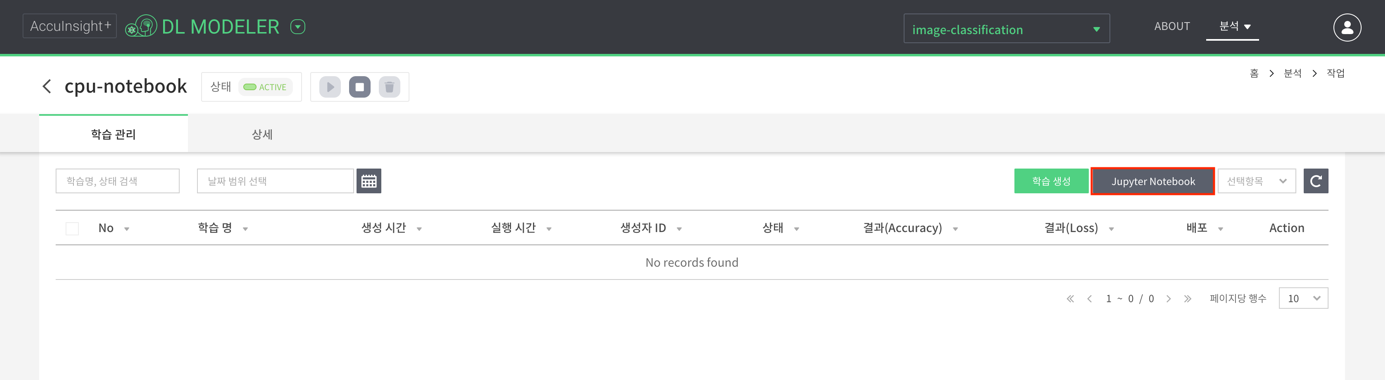
- custom 모드를 이용하여 jupyter notebook 환경이 생성되었기 때문에, basic 작업과 다르게 jupyter notebook 버튼이 보인다. 이 버튼을 클릭한다.
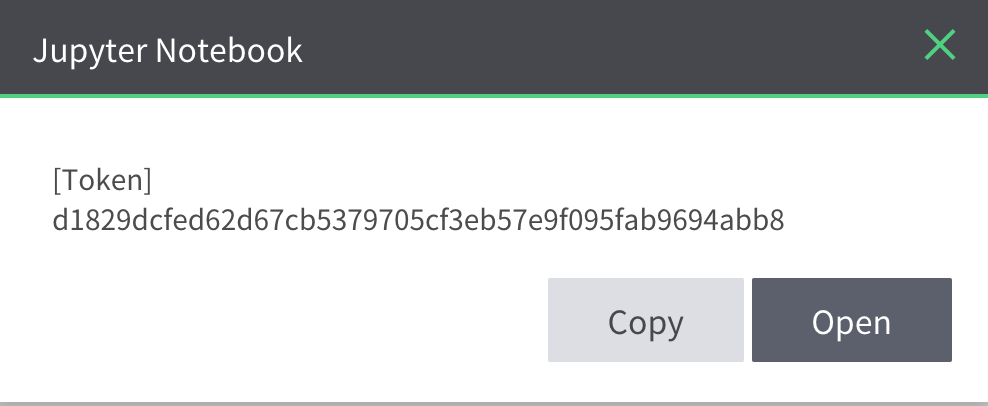
- jupyter notebook 버튼을 누르면 인증 토큰이 뜨는데, Copy 버튼을 누르면 토큰이 복사된다.
- 이후 Open을 클릭하여 노트북으로 진입한다.
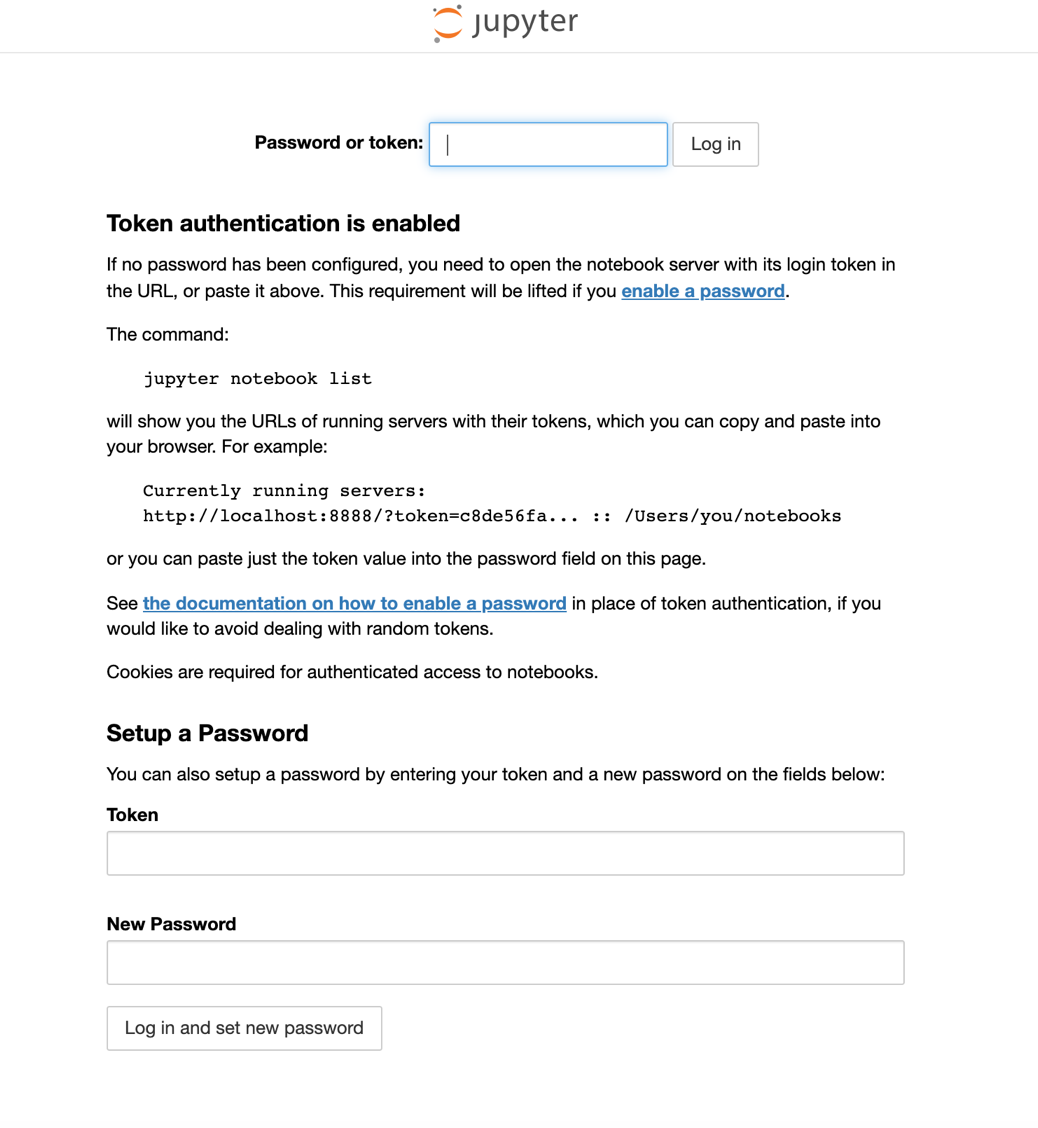
- jupyter notebook 로그인 화면이 뜬다. 로그인은 아까 복사했던 토큰으로 하면 된다.
- jupyter notabook 메인 작업 화면이다.
- 코드 작성을 위해 노트북을 하나 만든다.
- 우측 상단의 New 버튼을 클릭하면 python3 노트북을 선택할 수 있다.
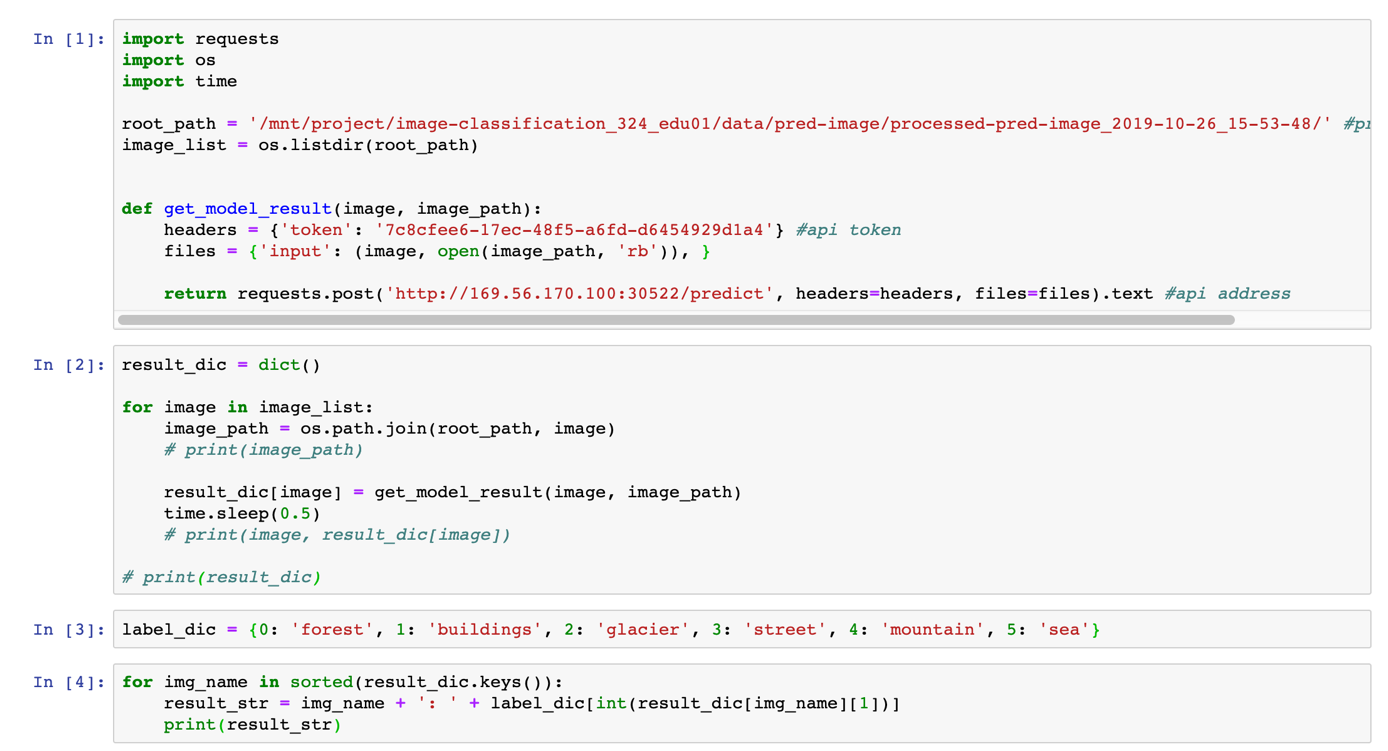
- 새 노트북에서 파이썬 코딩을 진행한다. 파이썬 코드는 jupyter notebook sample code 에서 복사할 수 있다.
[1] 번 블록
- 사용할 라이브러리를 호출한다.
- 예측할 대상이 되는 이미지가 있는 경로를 선언한다.
- API를 호출하는 함수를 만든다. API 호출 함수는 예측 관리 페이지의 상세 탭에 있는 curl API 예시를 파이썬 코드로 변환한 것이다.
- 다음은 14,034개 전체 데이터로 만든 모델의 API서버 정보이다.
- access token: 7c8cfee6-17ec-48f5-a6fd-d6454929d1a4
- 예측 API 주소: http://169.56.170.100:30522/predict
[2] 번 블록
- 이미지 명과 API를 호출해 얻은 분류 결과를 사전으로 매핑한다.
[3] 번 블록
- 정수로 반환되는 결과를 실제 카테고리로 매핑할 사전을 만든다.
[4] 번 블록
- API 호출 결과를 [3]에서 만든 사전을 이용하여 실제 카테고리로 변환한다.

- 분류 결과를 실제 카테고리로 변환해 본 결과이다.
sample code
- 아래 파이썬 파일은 위에서 jupyter notebook에서 만든 코드와 동일하다. (api_prediction.py)
- 7번째 줄 root_path 변수 값이 비어있다. 알맞은 값으로 채워 준다.
- 비어있는 부분('' 처리된 부분)에 예측하고자 하는 이미지가 들어 있는 image path(전처리해 두었던 폴더)를 넣어준다.
- get_model_result 함수 안에 있는 headers의 token 값과, post를 보내는 서버 주소를 변경하면 그 서버의 모델로 이미지를 예측하게 된다.
<
#api_prediction.py
import requests
import os
import time
root_path = '.' #pred image path
image_list = os.listdir(root_path)
def get_model_result(image, image_path):
headers = {'token': '7c8cfee6-17ec-48f5-a6fd-d6454929d1a4'} #api token
files = {'input': (image, open(image_path, 'rb')), }
return requests.post('http://169.56.170.100:30522/predict', headers=headers, files=files).text #api address
result_dic = dict()
for image in image_list:
image_path = os.path.join(root_path, image)
# print(image_path)
result_dic[image] = get_model_result(image, image_path)
time.sleep(0.5)
# print(image, result_dic[image])
# print(result_dic)
label_dic = {0: 'forest', 1: 'buildings', 2: 'glacier', 3: 'street', 4: 'mountain', 5: 'sea'}
for img_name in sorted(result_dic.keys()):
result_str = img_name + ': ' + label_dic[int(result_dic[img_name][1])]
print(result_str)
>