모니터링
Data drift 개요
학습된 분석모델은 계속해서 유입된 데이터 및 시간이 지남에 따라 성능이 저하 되는데 Data drift를 모니터링 하면 모델 성능 문제를 감지할 수 있습니다.(ex. 날씨 온도, 센서 수치, 은행 금리등)
- Data drift 알고리즘
Data drift를 계산하는 알고리즘이 여러 개 존재하지만 AccuInsight에서 KLD 알고리즘을 사용합니다.
Kullback–Leibler divergence(KLD)은 두 확률분포의 차이를 계산하는 데에 사용하는 함수로, 어떤 이상적인 분포에 대해, 그 분포를 근사하는 다른 분포를 사용해 샘플링을 한다면 발생할 수 있는 정보 엔트로피 차이를 계산합니다.
- AccuInsight에서 Data drift 사용 및 주의 사항
AccuInsight상에서 배포된 모델과 baseline/target dataset에 대해서 모니터링을 생성합니다. 선택한 feature 및 설정한 모니터링 주기에 따라 Data drift를 계산하며 기준치를 넘기게 되면 사용자에게 email 또는 slack으로 알람을 보냅니다. 이때, 모니터링을 생성할 때 주의할 점은 baseline 및 target dataset의 feature의 데이터 형식이 동일해야 하며 카테고리 데이터일 경우 인코딩 시켜줘야 합니다.(ex. 남자:0, 여자:1)
모델 모니터링 관리
Data drift 기반의 분석모델 성능 모니터링 기능을 제공합니다.
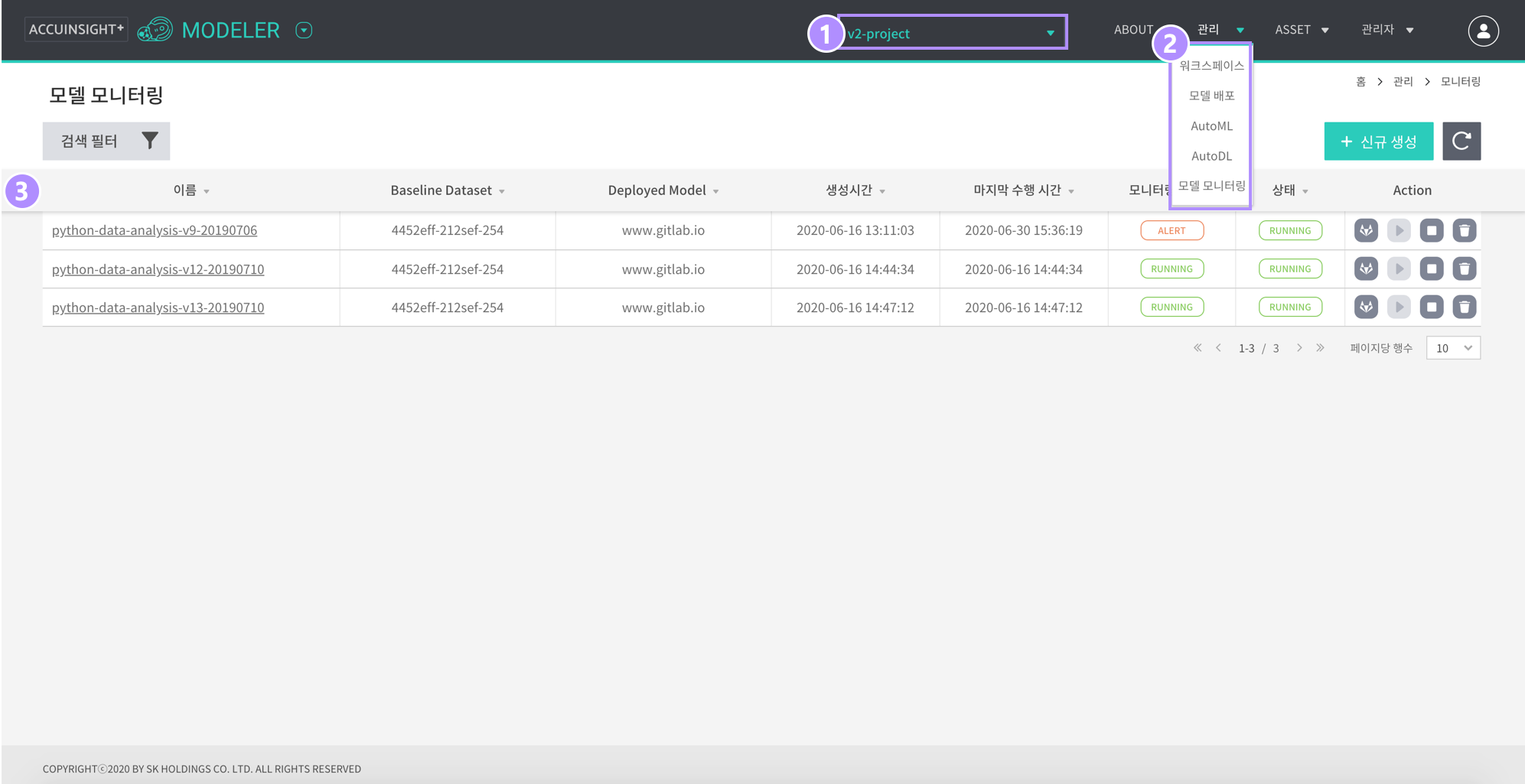
- 상단에서 프로젝트 선택
- 관리 메뉴에서 모델 모니터링 선택
- 테이블 목록
| 필드 | 설명 |
|---|---|
| 이름 | 모델 모니터링의 이름 |
| Baseline Dataset | Baseline Dataset 이름 |
| Deployed Model | 모니터링 대상 분석 모델 |
| 생성시간 | 모니터링 생성 일자 |
| 마지막 수행 시간 | Data Drift cronjob 마지막 수행 시간 |
| 모니터링 | 현재 분석모델의 성능 상태 표기 |
| RUNNING: 모델 성능이 정상적으로 실행중인 상태 | |
| ALERT: 설정한 Threshold보다 마지막 모니터링 수치가 높아 Alert 뜬 상태 | |
| 상태 | 현재 Data Drift cronjob의 상태 표기 |
| RUNNING: cronjob이 정상적으로 실행중인 상태 | |
| SUSPEND: cronjob이 멈춤 상태 | |
| Action | GitLab: 학습모델이 저장되어 있는 GitLab repository로 연결 |
| 시작: 중지중인 성는 모니터링 서비스의 재생성 | |
| 중지: 성능 모니터링 리소스를 중지(삭제) | |
| 삭제 : 성능 모니터링 리소스 삭제 및 관련 정보 삭제 |
모델 모니터링 생성
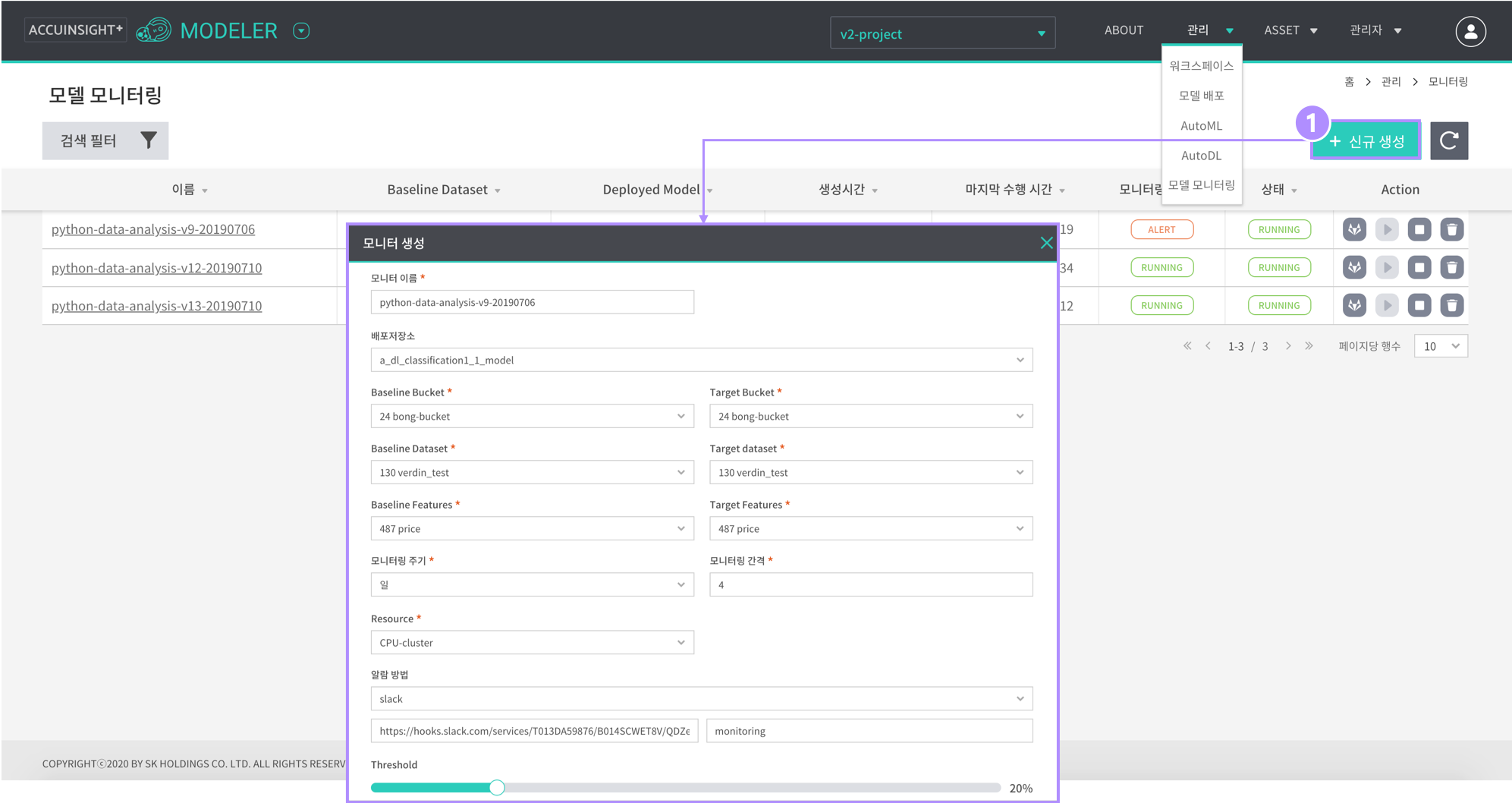
- 모델 모니터링 생성
- 우측 상단의 ‘+ 신규 생성’ 버튼을 눌러 모니터링 생성
- 모니터 이름 중복 생성 불가
- 모니터 생성 입력 필드:
- 모니터 이름: 모니터링 이름 입력
- 배포저장소: 모니터링할 학습 모델 선택
- Baseline Bucket: 기준 데이터의 Datacatalog상에 등록된 버킷
- Target Bucket: 타깃 데이터의 Datacatalog상에 등록된 버킷
- Baseline Dataset: 기준 데이터의 Datacatalog상에 등록된 데이터셋
- Target Dataset: 타깃 데이터의 Datacatalog상에 등록된 데이터셋
- Baseline Features: 모니터링할 기준 데이터의 피쳐
- Target Features: 모니터링할 타깃 데이터의 피쳐
- 모니터링 주기: 모니터링 주기 설정 (ex : 5 시간마다)
- 알람 방법 (slack): slack webhook url 및 알람을 받을 channel 입력
- 알람 방법 (email): 알람을 받을 email 주소 입력
- threshold: datadrift의 알람 기준 설정
모델 모니터링 결과
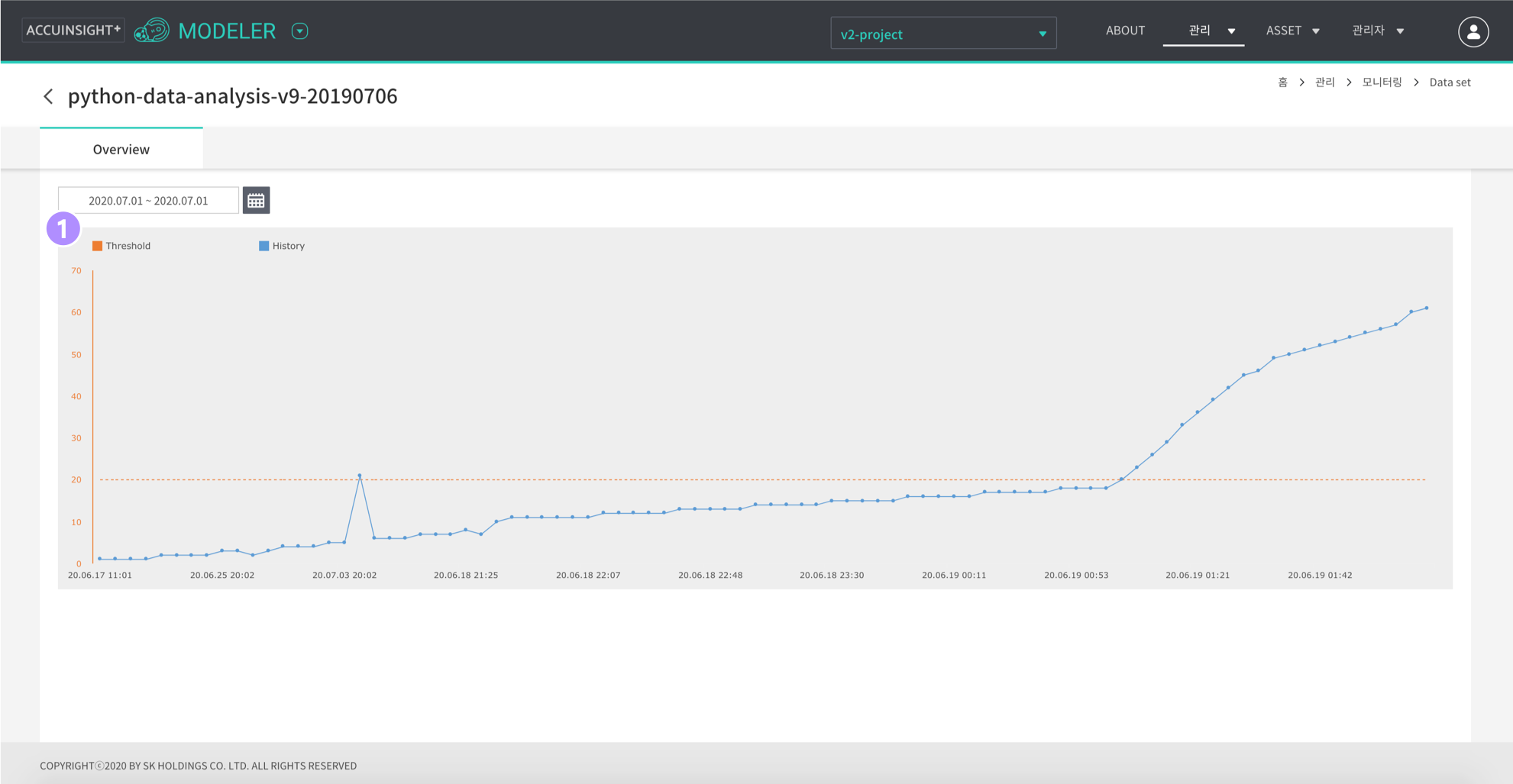
- 모델 모니터링 결과
- Data Drift의 결과 추이 그래프 확인