워크스페이스
워크스페이스 관리
워크스페이스는 Rstudio, Jupyter Lab/Notebook이 설치된 가상 컴퓨팅 환경입니다.
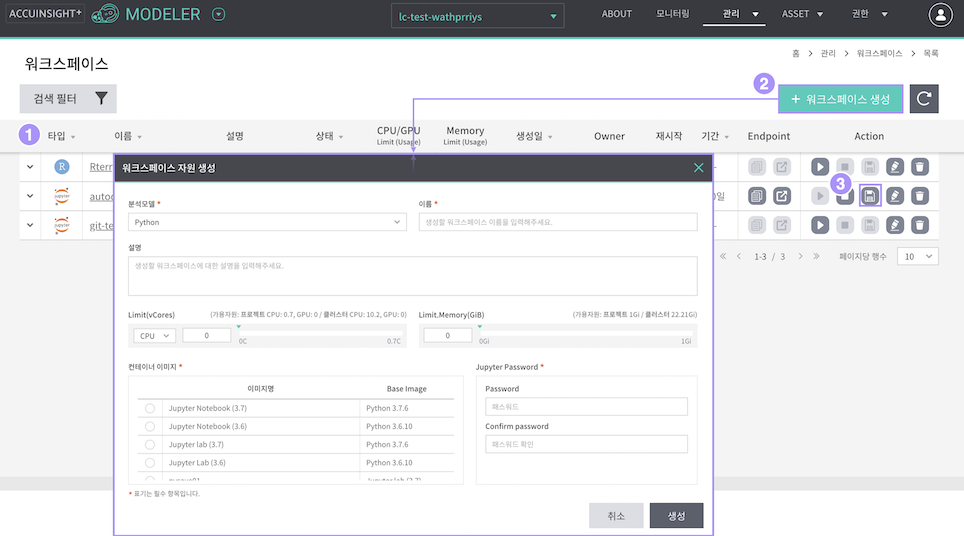
워크스페이스 목록
필드 설명 타입 분석 Tool 타입 (Jupyter Lab/Notebook, R studio) 이름 워크스페이스를 대표하는 제목 설명 워크스페이스에 대한 설명 상태 현재 워크스페이스 상태 표기 PENDING: 컨테이너 실행 및 리소스 설치가 실패된 상태 RUNNING: 컨테이너가 정상적으로 실행 중인 상태 TEMINATED: 리소스는 사용 중이지만 컨테이너가 종료 됨 WAITING: 컨테이너를 초기화하는 상태 STOPPED: 컨테이너 리소스는 삭제되고 메타정보만 저장된 상태 N/A: 상태 알 수 없음 CPU/GPU 워크스페이스 별 할당 CPU 혹은 GPU core 수 및 실제 사용율(%) 표시 Memory 워크스페이스 별 할당 Memory 정보 및 실제 사용율(%) 표시 생성일 생성일, 시 표기 Owner 생성자 정보 표기 재시작 재시작 횟수 기간 생성 이후의 시간 Endpoint R studio/Jupyter 접속 URL 복사 / 바로가기 Action 시작 : 중지 상태의 워크스페이스의 컨테이너 리소스를 재생성. 중지 시 컨테이너 사본 "저장 후 중지" 한 경우 저장된 정보로 재생성 중지: 컨테이너 리소스를 중지(삭제) (컨테이너 사본 "저장 후 중지"/"저장하지 않고 중지" 선택 가능) 컨테이너 이미지 저장 : 생성된 컨테이너 이미지 저장. 프로젝트/서비스전체 공유가능. 워크스페이스 신규 생성 시 저장된 custom image 사용 가능) 수정 삭제: 워크스페이스 생성/실행 관련 정보 모두 삭제. 동일 정보로 재생성/수정 불가
- 워크스페이스 생성
- 컨테이너 이미지 저장
- 생성되어 있는 워크스페이스의 컨테이너이미지 저장. (설치된 라이브러리/패키지 정보가 포함된 컨테이너 이미지 정보 저장)
- [Asset]> [워크스페이스이미지] 메뉴를 통해 관리
- 워크스페이스 신규 생성 시 공유레벨("공유하지않음"/"프로젝트내 공유"/"서비스 전체 공유") 기준으로 해당 저장된 Custom Image 를 조회 및 선택하여 워크스페이스 생성 가능
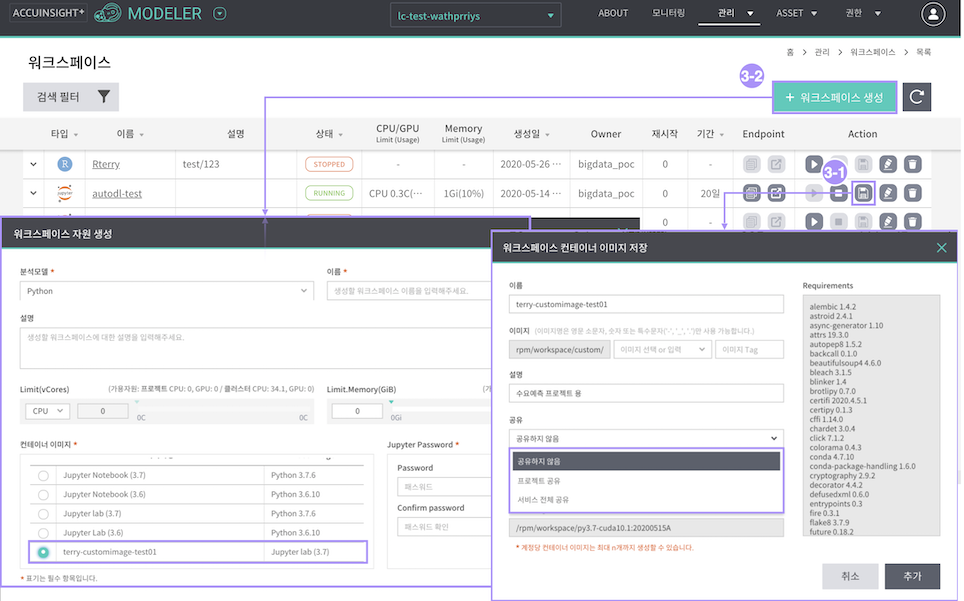
워크스페이스 상세 정보 관리
워크스페이스 상세페이지는 해당 컨테이너의 상세 정보를 조회하고 분석툴에서 생성한 파일을 조회하고 저장소로 저장할 수 있습니다.
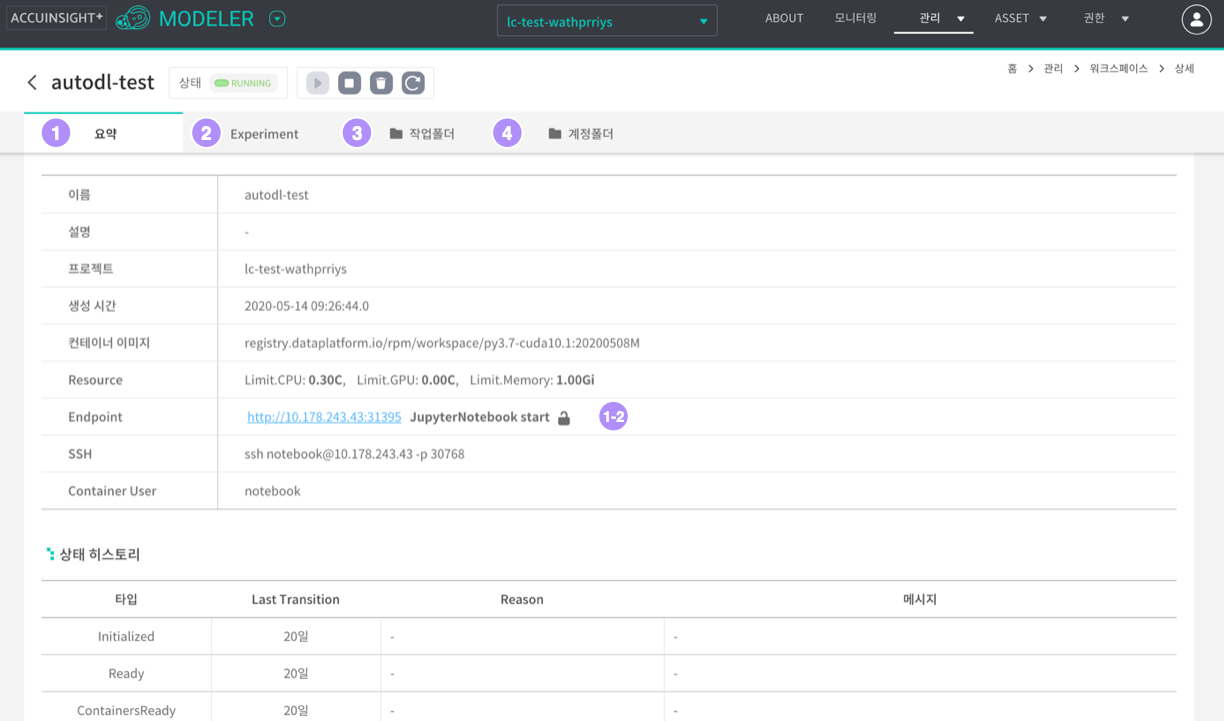
- 요약
- Experiment
- 작업폴더
- 계정폴더
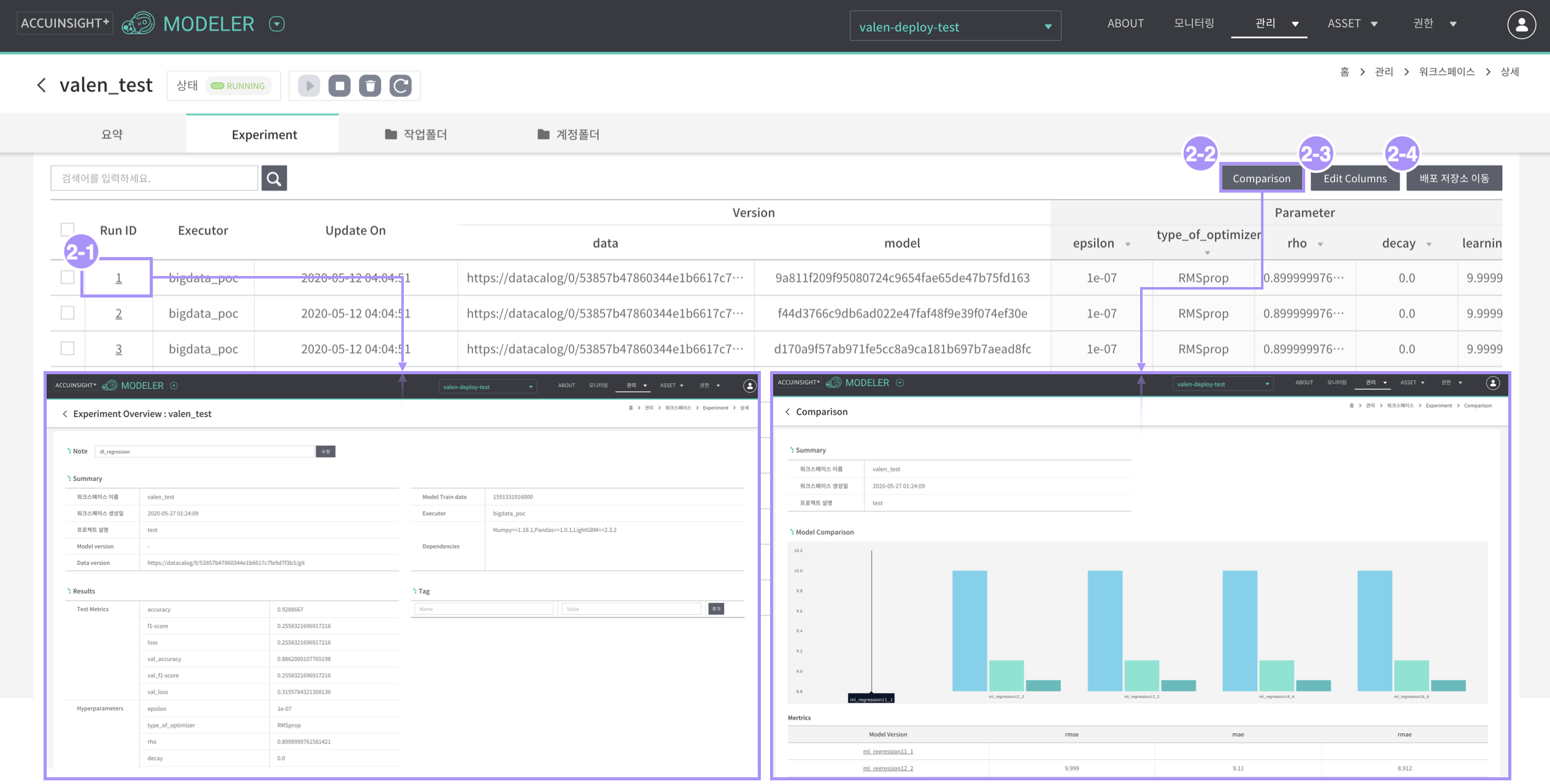
워크스페이스 > Experiment > AccuInsight SDK
Experiment에 학습된 모델을 등록하기 위한 Python sdk인 Accuinsight 를 제공합니다.
Accuinsight 는 학습에 사용된 machine learning platform에 따라 3가지 api로 구분되며, 사용자 편의를 위한 utils 를 포함합니다.
Tensorflow 2.0의 estimator로 작성된 모델과 Pytorch는 현재 지원하지 않습니다.
API 소개
API 공통 기능
(method) set_storage( access_key, secret_key, region, bucket_name, hdfs_uri, file_path, target, save_json, save_path )accu.set_storage(file_path=/home/work/boston_data.csv, target='MEDV')모델링에 사용하고자 하는 데이터를 SDK에 등록합니다. data drift 기능을 활용하기 위해서 필요한 작업입니다.
Accuinsight+의 Data Catalog와 HDFS, Amazon S3를 지원합니다. 또는 노트북에 존재하는 파일을 등록할 수도 있습니다.
저장소 종류에 따라 필요한 인수(argument)가 다릅니다. 필수 인수는 file_path와 target 입니다.
저장소 정보를 json file로 저장해 둘 수 있습니다. 이 json_file은 아래의 get_file() 메소드에서 활용됩니다.
json file을 저장할 경로를 지정할 수 있습니다. 지정하지 않을 경우 현재 경로에 저장합니다.
Arguments
access_key: AWS S3 저장소의 access key를 입력합니다 (AWS S3). secret_key: AWS S3 저장소의 secret key를 입력합니다 (AWS S3). region: AWS S3 저장소의 region을 입력합니다 (AWS S3). bucket_name: AWS S3 저장소의 bucket name을 입력합니다 (AWS S3). file_path: 저장소 내의 파일 경로를 입력합니다 (공통, 필수 argument). target: target(y) 변수명을 입력합니다 (공통, 필수 argument). save_json: 저장소 정보를 저장하고 싶을 경우, True로 지정합니다 (공통). save_path: 저장소 정보를 저장할 경로를 지정합니다 (공통).(method) get_file( storage_json_file_name )
accu.get_file(storage_json_file_name)모델링에 사용하고자 하는 데이터가 저장된 저장소에서 데이터를 다운로드 받습니다.
저장소 정보를 json file로 넘겨줄 수 있습니다. json file이 입력되지 않으면 set_storage 메소드에서 등록한 데이터를 불러옵니다.
다운로드 완료 후, 로그 메시지에 기록된 path를 사용하여 직접 데이터를 불러옵니다.
Arguments
storage_json_file_name: 다운로드 받을 데이터 정보를 담은 json file의 경로를 입력합니다 (선택 사항).accu.get_file('/home/work/boston_data.csv')학습에 사용할 데이터가 노트북에 있는 데이터인 경우, 이 과정은 생략할 수 있습니다.
(method) set_features( feature_names = [feature_list])
accu.set_features(feature_names=['MEDV', ''])데이터를 불러온 후, 테이블 구조 변경으로 features 정보가 변경되었을 경우 사용합니다.
노트북에서 데이터를 변경한 경우 변경한 테이블을 자동으로 다시 인식하므로, 이 메소드를 사용할 필요가 없습니다.
Arguments
feature_names: features list. python list 또는 pandas dataframe 형태로 넣어 주어야 합니다.(method) set_slack( hook_url = 'slack_webhook_url')
accu.set_slack(hook_url='https://hooks.slack.com/services/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')모델 학습이 완료되거나, 모델 학습 도중 사용자가 설정한 조건을 만족하는 경우, Slack으로 메시지를 받아보실 수 있습니다.
set_slack()메소드를 호출하여 slack 채널의 webhook url을 먼저 설정해주어야 합니다.Arguments
hook_url: Slack 채널의 webhook urlslack webhook url은 slack workspace에 incoming webhook을 추가하면 가져올 수 있습니다.
slack webhook url로 메시지를 받을 채널이나 DM을 지정할 수 있습니다.
여러 개의 채널에 알람을 보내고 싶을 경우, ',' 로 구분하여 넣어줍니다.
(method) set_mail( address = 'mail_address')
```pythonaccu.set_mail(address='hyunjoong@sk.com')```- Slack과 더불어, E-mail로도 메시지를 받아보실 수 있습니다.- `set_mail()` 메소드를 호출하여 메일 주소를 먼저 설정해주어야 합니다.- ___Arguments____address_: 수신할 메일 주소- 여러 개의 메일로 알람을 보내고 싶을 경우, ',' 로 구분하여 넣어줍니다.(method) send_message( message* = 'message', thresholds** = 0.7 )
# case 1 - 학습 완료 메시지를 푸시할 경우accu.send_message(message='학습이 완료 되었습니다.')# case 2 - metric이 thresholds 초과시 메시지를 푸시할 경우accu.send_message(thresholds=0.7)위의 example과 같이, 경우에 따라 사용되는 Arguments 의 차이가 있습니다.
Arguments
message: 모델 완료시 받고자 하는 메시지
thresholds: 알람을 받고자 하는 metric의 임계치두 가지 Arguments 를 동시에 사용할 수 없습니다.
ML experiment의 경우, thresholds argument를 사용할 수 없습니다. message argument를 사용해 주십시오.
(method) unset_slack()
accu.unset_slack()slack alarm 설정을 해제합니다.
이 메소드는 argument 없이 동작합니다.
(method) unset_slack()
```pythonaccu.unset_mail()```- mail alarm 설정을 해제합니다.- 이 메소드는 argument 없이 동작합니다.(method) unset_message()
accu.unset_message()alarm 메시지 설정을 해제합니다.
이 메소드는 argument 없이 동작합니다.
ML API
[link] ML API example(class) accuinsight()
from Accuinsight.Lifecycle.ML import accuinsightaccu = accuinsight()- accuinsight() class를 임의의 변수(accu)로 선언합니다.
(class) add_experiment( model_name, X_test, y_test )
y_pred = model.predict(X_test)mse = sklearn.metric.mean_squared_error(y_test, y_pred)mae = sklearn.metric.mean_absolute_error(y_test, y_pred)with accu.add_experiment(model_name, X_test, y_test) as exp:exp.log_params('alpha')exp.log_params('beta')exp.log_metrics('MSE', mse)exp.log_metrics('MAE', mae)exp.log_tag('model-test')- add_experiment 는 학습된 모델을 등록하는 데 사용되는 class로, with 구문에서 아래의 메소드를 수행합니다.
- (method) log_params( 'hyperparameter name' )
모델 학습에 사용된 모델의 hyperparameter를 기록합니다. - (method) log_metrics( 'metric name' , defined_metric )
모델로 예측을 수행한 후, 계산된 metric(defined_metric)을 기록하고자 하는 이름('metric name')과 함께 입력해줍니다. - (method) log_tag( 'model description' )
모델에 대한 간단한 설명을 기록합니다.
- (method) log_params( 'hyperparameter name' )
- Arguments
model_name: 학습된 모델의 이름 X_test: 평가에 사용될 input dataset의 이름 y_test: 평가에 사용될 target dataset의 이름
- multiclass classification에서 SVC 를 사용하여 모델링 할 경우,
probability = True옵션 설정이 필요합니다. - multiclass classification에서 LinearSVC 를 사용하여 모델링 한 경우,
predict_proba()를 제공하지 않아 ROC/Precision-recall curve가 제공되지 않습니다.
keras API
[link] keras API example(class) accuinsight()
from Accuinsight.Lifecycle.keras import accuinsightaccu = accuinsight()- accuinsight() class를 임의의 변수(accu)로 선언합니다.
(class) autolog( tag = 'model description' )
accu.autolog(tag = 'keras-test')- autolog 는 keras의
fit()메소드를 수행하기 이전에 선언한 후,fit()을 통해 모델을 학습시키면, 학습 과정에서 자동으로 Experiment를 등록합니다.- autolog 를 선언하면, 모델 학습 종료 시점에 가장 좋은 metric을 갖는 epoch의 weight가 자동으로 설정됩니다. 단, 이 때
fit()메소드에 입력된 epoch만큼 학습이 진행되므로 빠른 학습 종료를 위해서는 early_stopping 콜백을 추가해야 합니다. - autolog 는 가장 좋은 metric을 기록한 epoch에서의 모델 정보와 weight를 저장합니다. 따라서 이전에 저장된 모델을 불러와 공동 작업자들과 공유하거나, 재학습을 수행할 수 있습니다. 모델을 불러오는 메소드는 utils 항목을 참고하세요.
- autolog 를 선언하면, 모델 학습 종료 시점에 가장 좋은 metric을 갖는 epoch의 weight가 자동으로 설정됩니다. 단, 이 때
- Arguments
tag: 모델에 대한 간단한 설명> `model.compile()` 시, _metrics_ 리스트에서 처음으로 입력 된 평가지표를 활용하여 모델을 훈련합니다. 따라서 모델 훈련 시 기준이 되는 평가 지표를 먼저 입력해야 합니다. 예를 들어 위와 같이 모델을 컴파일 한 경우, 모델 훈련 시 _f1_score_ 를 참조하여 가장 좋은 _f1_score_ 를 기록한 모델을 기록하고, 적합시킵니다.```pythonmodel.compile(metrics = [f1_score, accuracy])```
tensorflow API
API 구조는 keras API와 동일합니다.(_class_) __accuinsight()__ ```python from Accuinsight.Lifecycle.tensorflow import accuinsight
tensorflow API exampleaccu = accuinsight()
- accuinsight() class를 임의의 변수(_accu_)로 선언합니다.(_class_) __autolog(__ _tag_ = '_model description_' __)__```pythonaccu.autolog(tag = 'tensorflow-test')- autolog 는 keras의
fit()메소드를 수행하기 이전에 선언한 후,fit()을 통해 모델을 학습시키면, 학습 과정에서 자동으로 Experiment를 등록합니다.- autolog 를 선언하면, 모델 학습 종료 시점에 가장 좋은 metric을 갖는 epoch의 weight가 자동으로 설정됩니다. 단, 이 때
fit()메소드에 입력된 epoch만큼 학습이 진행되므로 빠른 학습 종료를 위해서는 early_stopping 콜백을 추가해야 합니다. - autolog 는 가장 좋은 metric을 기록한 epoch에서의 모델 정보와 weight를 저장합니다. 따라서 이전에 저장된 모델을 불러와 공동 작업자들과 공유하거나, 재학습을 수행할 수 있습니다. 모델을 불러오는 메소드는 utils 항목을 참고하세요.
- autolog 를 선언하면, 모델 학습 종료 시점에 가장 좋은 metric을 갖는 epoch의 weight가 자동으로 설정됩니다. 단, 이 때
- Arguments
tag: 모델에 대한 간단한 설명> `model.compile()` 시, _metrics_ 리스트에서 처음으로 입력 된 평가지표를 활용하여 모델을 훈련합니다. 따라서 모델 훈련 시 기준이 되는 평가 지표를 먼저 입력해야 합니다. 예를 들어 아래와 같이 모델을 컴파일 한 경우, 모델 훈련 시 _f1_score_를 참조하여 가장 좋은 f1_score를 기록한 모델을 기록하고, 적합시킵니다.```pythonmodel.compile(metrics = [f1_score, accuracy])```
- autolog 는 keras의
utils
(method) load_data( run_name = 'Run_name' )from Accuinsight.Lifecycle.utils import load_dataload_data('keras-AB123CD56EFG')- 과거에 학습되어 Experiments에 기록된 모델을 재사용하고자 할 경우, 해당 모델의 'Run Name'을 통해 모델을 불러올 수 있습니다.
- Workspace 목록에서 특정 workspace명 옆의 [v]를 클릭하면, Experiments 요약정보를 다음과 같이 확인하실 수 있습니다.
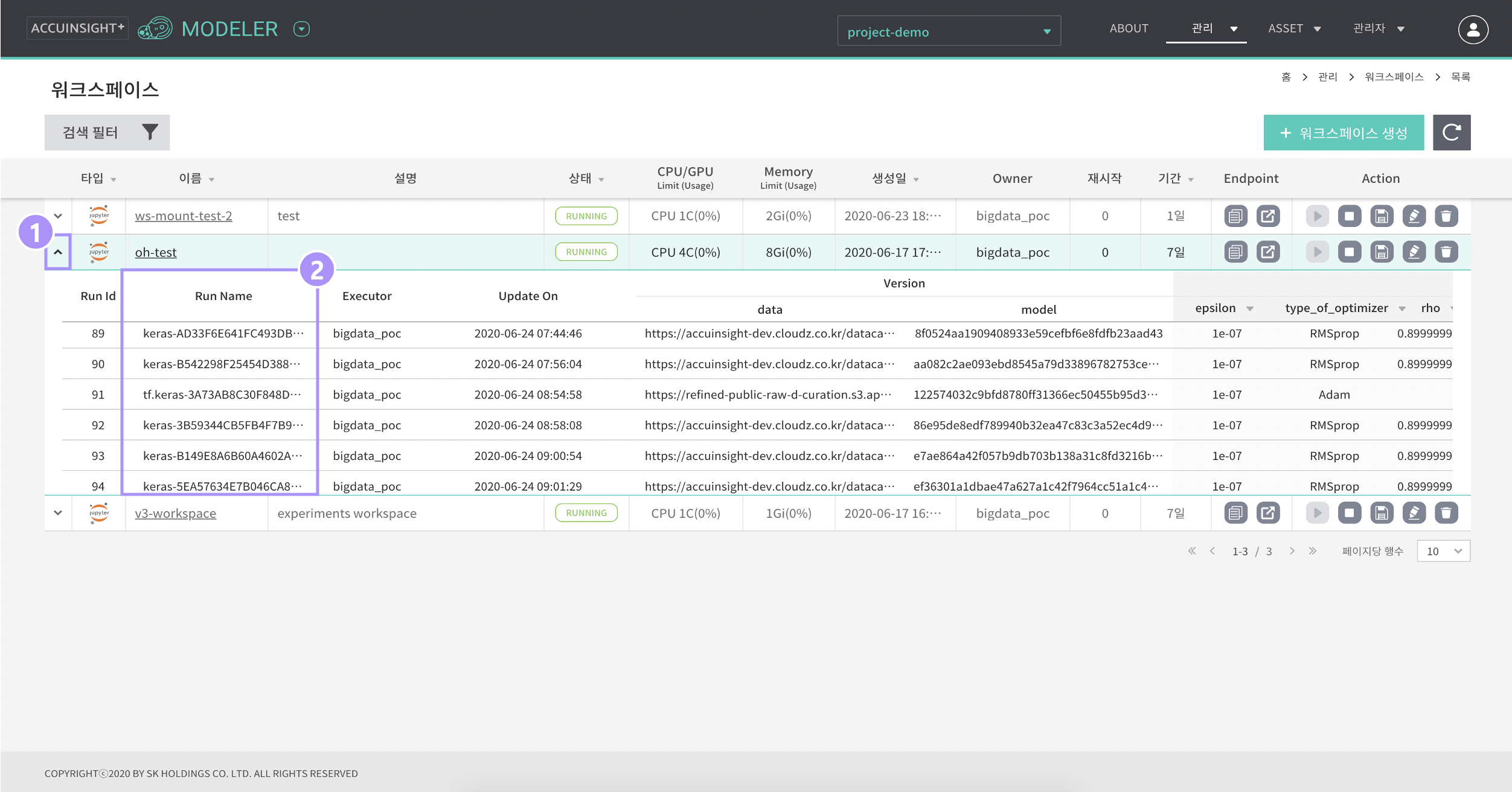
- 'Run Name' 칼럼의 값을 복사하여 원하는 모델을 불러오는데 사용하시면 됩니다.
- Arguments
run_name: 불러오고자 하는 모델의 Experiment Run Name을 복사하여 입력합니다.
워크스페이스 > 소스 저장소 저장
워크스페이스 작업폴더의 소스를 소스 저장소로 저장할 수 있습니다.
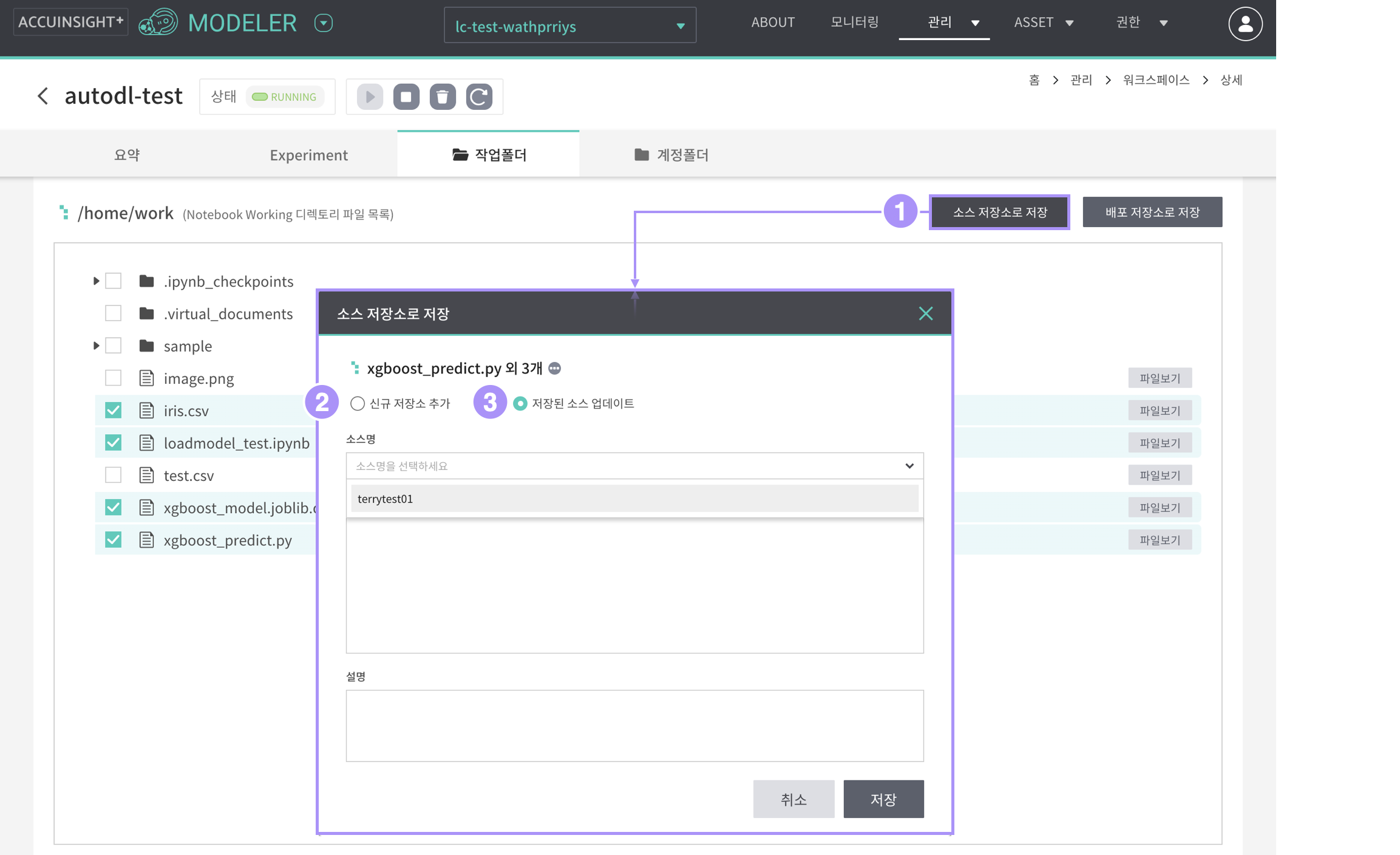
- 소스 저장소로 저장
- 신규소스 추가
- 저장된 소스 업데이트
워크스페이스 > 배포 저장소 저장
워크스페이스 작업폴더의 모델을 배포 저장소로 저장할 수 있습니다.
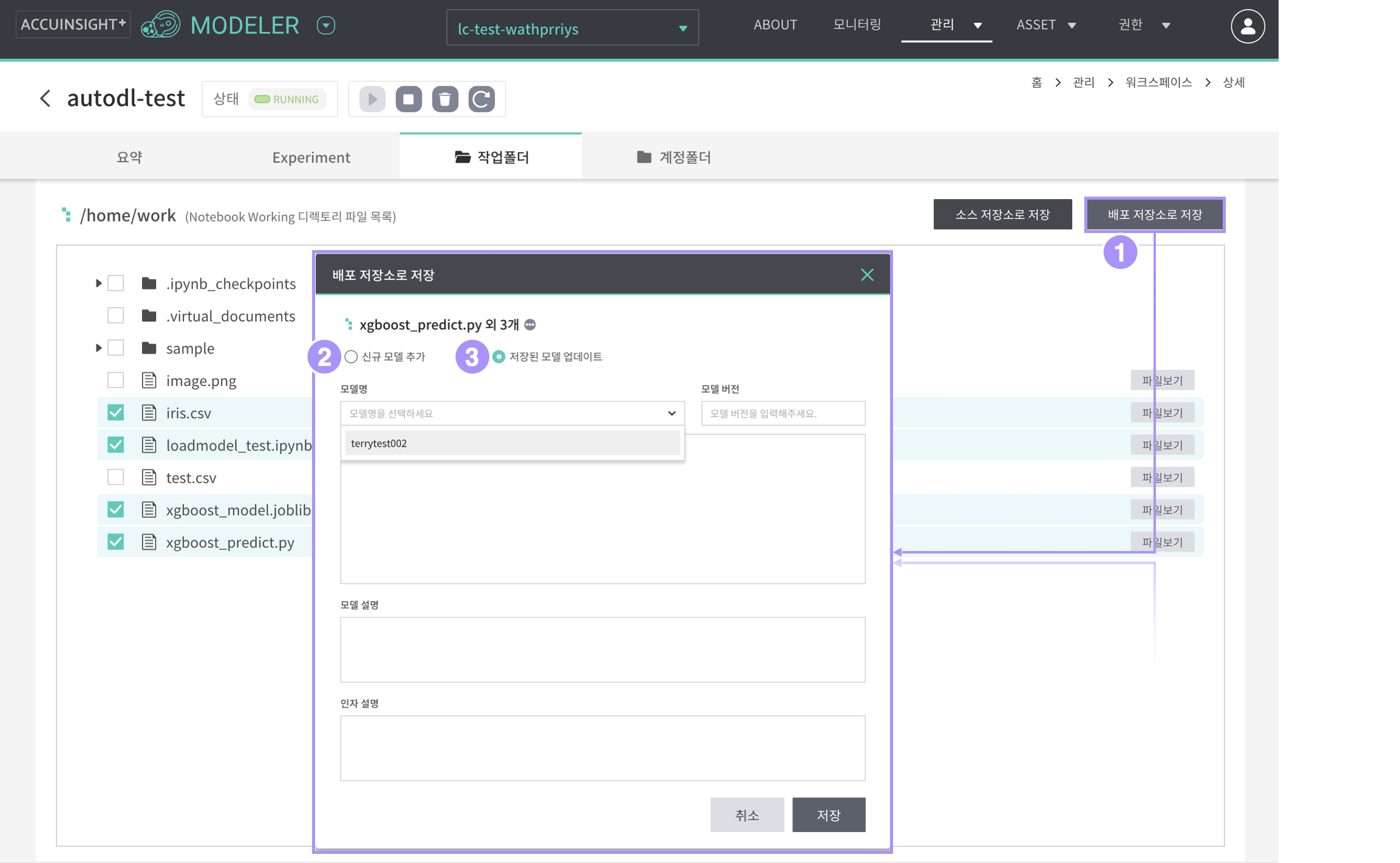
- 배포저장소로 저장
- ‘신규모델 추가’ 또는 ‘저장된 모델 업데이트’를 선택하여 저장
- 신규모델 추가
- 모델을 새로운 이름으로 배포 저장소에 저장
- 저장된 모델 업데이트
- 기존에 저장된 모델에 새로운 버전을 발행하여 배포 저장소에 저장
- 배포 저장소로 저장시, 사용자는 모델에 명시적으로 버전을 지정해야 함
Note
저장된 모델을 업데이트 시, 모델 버전은 이전보다 높은 버전이어야 함 (ex. 기존 버전: 1.0.1 인 경우 -> 신규 버전: 1.0.0 (x), 1.0.1(x), 1.1(o), 1.0.2(o))