HDFS 내보내기
HDFS 내보내기
워크플로우 실행 결과를 hdfs에 저장하기 위해 사용하는 노드이다. 좌측 [데이터내보내기]노드 중 [HDFS내보내기]노드를 drag & drop 한다. Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있다.
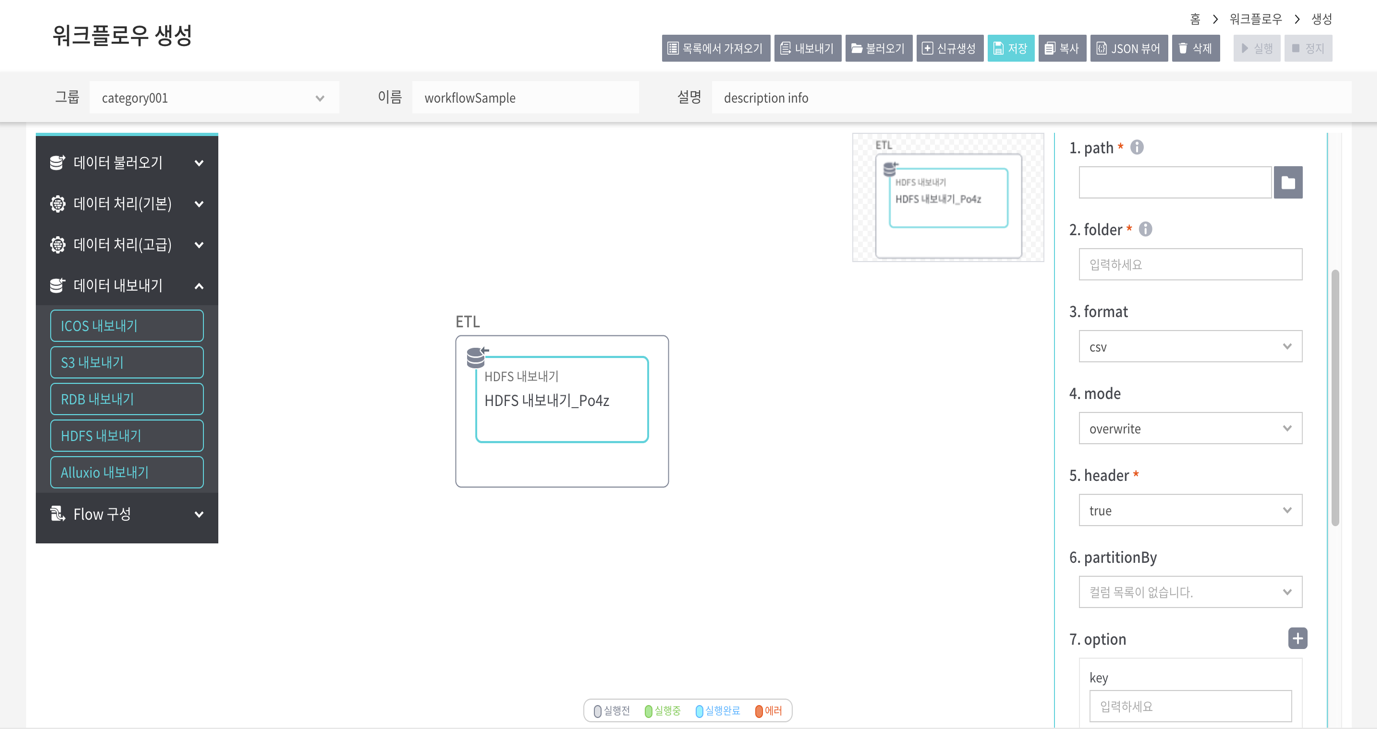
path : 데이터를 저장할 hdfs 경로 설정
folder : 데이터를 저장할 폴더명. 날짜 표현식을 입력하여 해당 날짜로 치환할 수 있다. 날짜 표현식과 관련한 Guide는 아래와 같다.
- 날짜 표현식 : #{now:날짜 포맷}
- 현재 날짜가 2019년 7월 3일 12시인 경우 아래와 같이 표현 가능
표현식 설명 #{now:yyyyMMdd} 오늘 날짜 20190703 으로 치환 #{now-1d:yyyy-MM-dd} 어제 날짜 2019-07-02로 치환 #{now-1w:yyyyMMddHH} 1주일전 날짜 2019062612로 치환 - /test/#{now:yyyyMMdd} 로 지정시 /test/20190703 이란 디렉토리로 치환된다.
format : 저장 포맷을 설정할 수 있다(json, orc, parquet, csv, text 중 택1).
mode : 저장모드를 설정한다. 선택가능한 저장모드는 아래와 같다.
mode 설명 error 파일이 있으면 에러 처리 append 다른 이름으로 파일 추가 overwrite 기존 파일을 삭제하고 추가 ignore 파일이 있으면 저장하지 않고, 에러 처리도 하지 않음 header : 헤더 여부 (true, false 중 택1)
partitionBy : 특정 컬럼에 대해 Partitioning 하여 데이터를 저장 할 수 있다(컬럼 데이터별로 하위 폴더가 생성됨).
option : key, value 설정 (null을 문자열로 인식하는 것을 방지 할 수 있음.)
highAvailability : 네임노드의 HA구성 여부를 결정
nameservices : nameNode 명을 기재
namenode1 : 이중화 nameNode 의 첫번째IP
namenode2 : 이중화 nameNode 의 두번째IP
Example
test1234 클러스터에 적재된 서울특별시 대기오염 측정정보(2019년기준, 출처 : 공공데이터포털, https://www.data.go.kr)를 sampling 하여 이를 다시 hdfs에 저장한다. 저장폴더에는 날짜표현식을 적용한다.
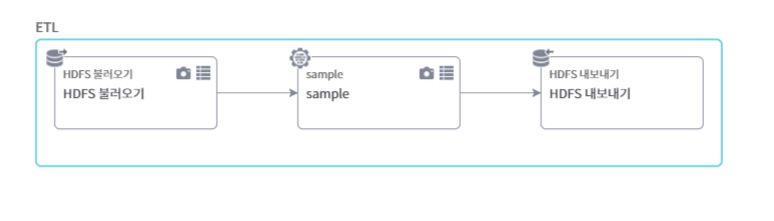
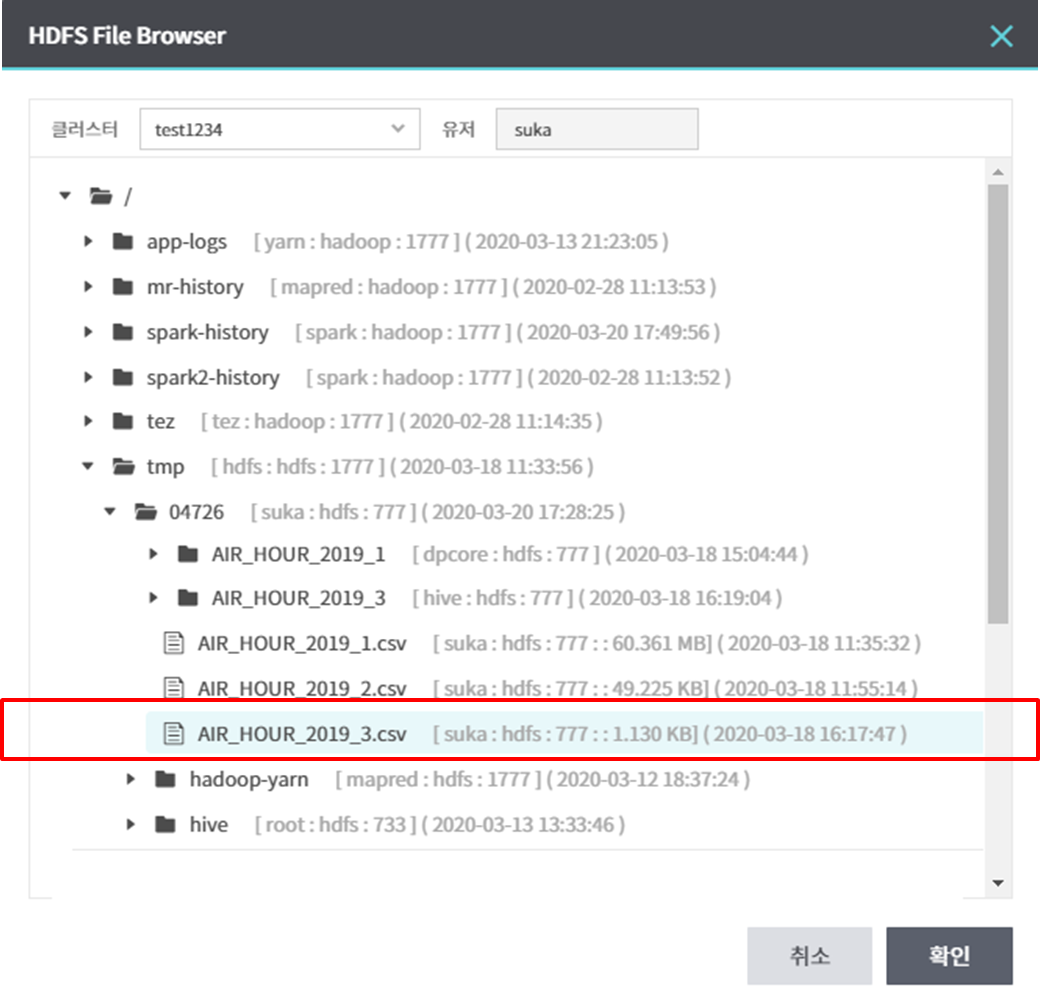
- 데이터 불러오기 경로 : hdfs://test1234-accu-hdfs-nn.suka:9000/tmp/04726/AIR_HOUR_2019_3.csv
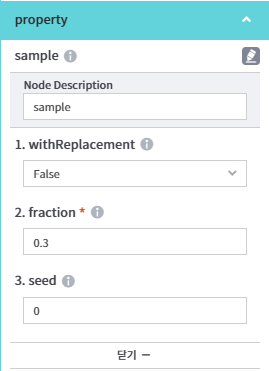
- sample 노드의 경우 비복원방식으로 30%만 추출하도록 설정했다.
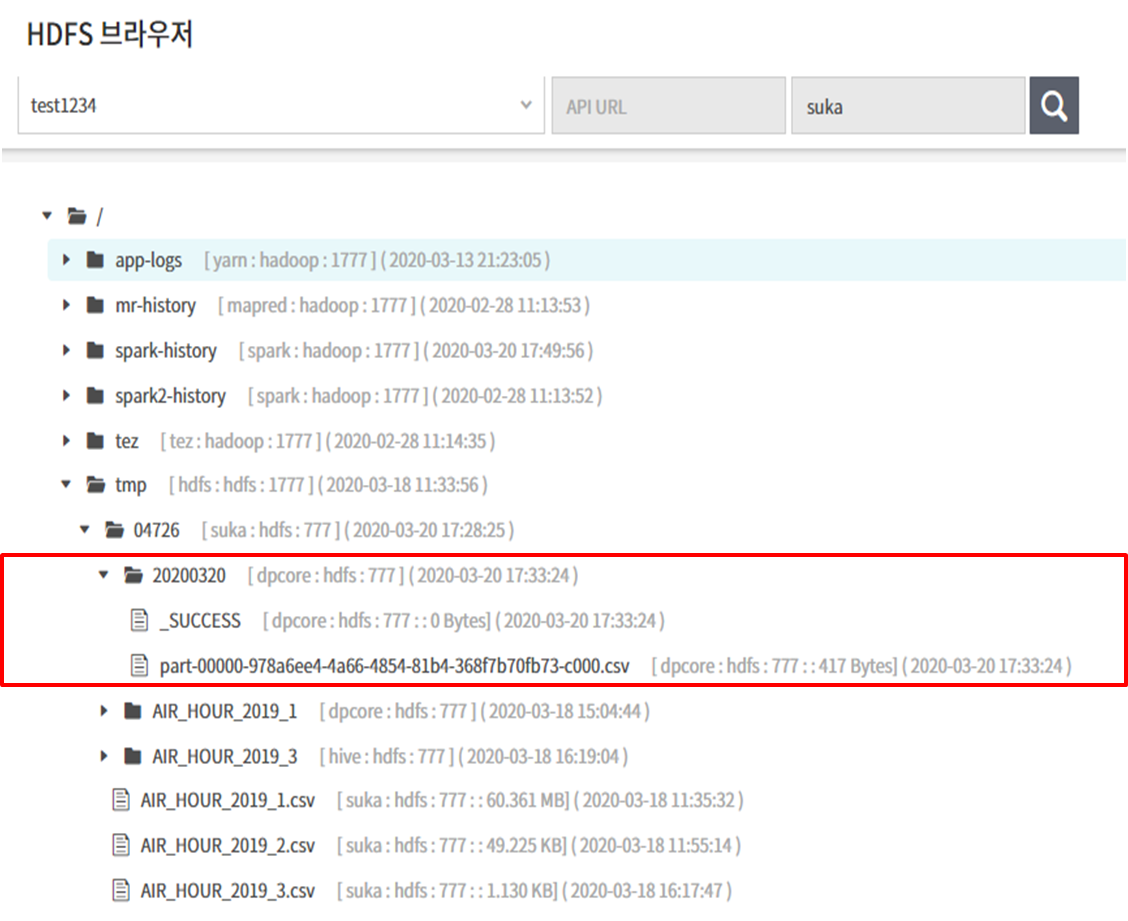
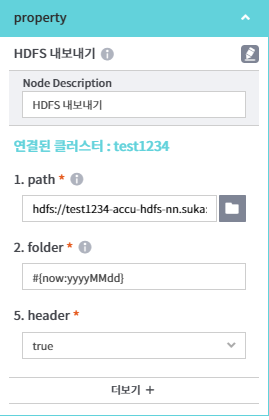
- HDFS 내보내기의 경우 property 패널의 2.folder에 날짜표현식을 적용했다. 샘플링 결과를 오늘날짜의 폴더를 만들어 적재한다.
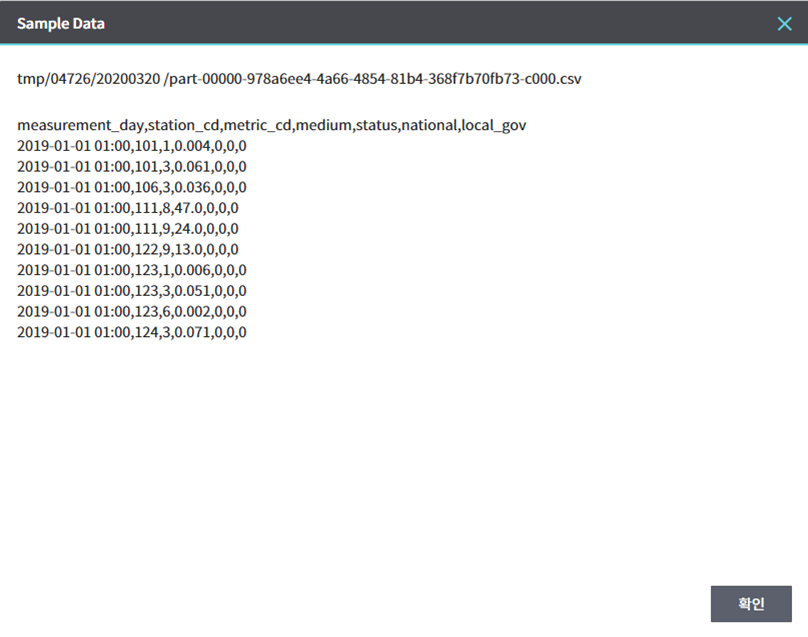
위 Example 실행결과로 아래 경로에 샘플링 데이터가 추출됐다.