S3 불러오기
S3 불러오기
Amazon S3에 저장된 데이터를 Batch Pipeline으로 불러오기 위해 사용하는 노드이다.
- File 브라우저를 통해 데이터가 저장된 스토리지와 등록된 버킷을 선택할 수 있다. 버킷이 없을 경우 File 브라우저의 [Bucket 관리] 또는 [브라우저] > [S3] 메뉴에서 버킷 정보를 등록 할 수 있다.
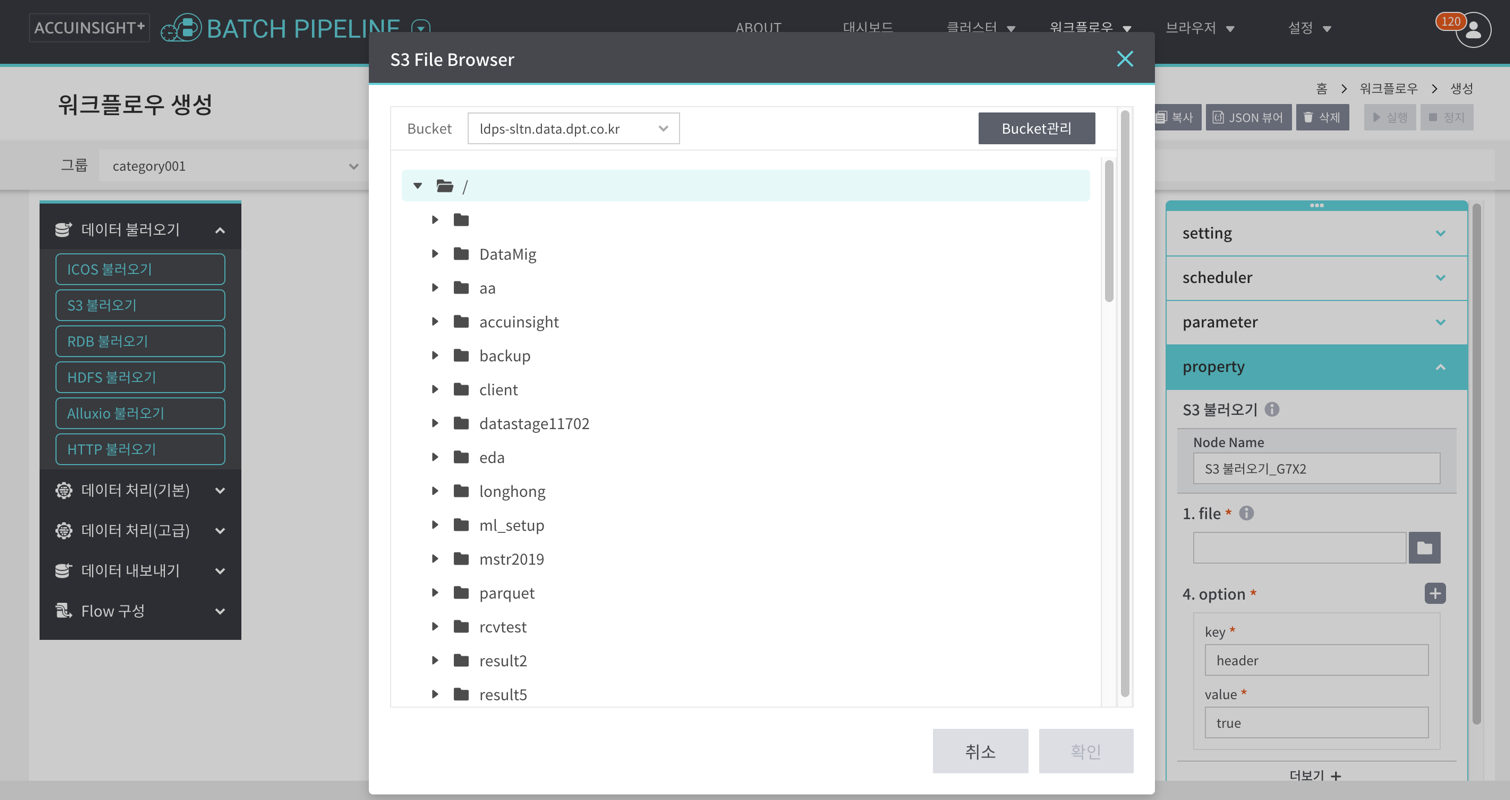
- S3에 저장된 데이터의 Delimiter와 header 포함여부를 선택할 수 있다.
- Schema를 자동 파싱하여 이후 구성할 ETL 작업에서 사용할 수 있다.
좌측 [데이터불러오기]노드 중 [S3불러오기]노드를 drag & drop 한 후 Property 항목을 입력한다. Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있다.
- file : File 브라우저에서 데이터가 저장된 스토리지와 버킷을 입력한다.
- format : 불러올 파일의 형식을 정한다(json, parquet, csv 중 택1).
- delimiter : 구분자를 입력한다.
- option : 사용 가능한 옵션을 설정한다.
- key: header, value : true = 헤더 설정 여부
- key: nullValue, value : Null = Null 문자열 처리
- key: nanValue, value : NaN = NaN 문자열 처리
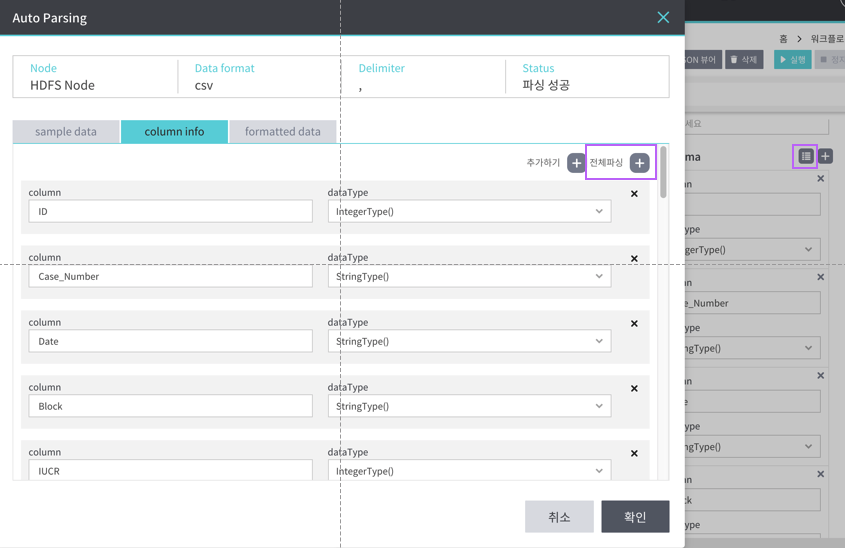
- schema : column 및 dataType을 정의한다(우측 버튼 이용하여 전체 파싱 및 일부 추가 가능).
- credential : File 브라우저에서 스토리지, 버킷정보를 입력하면 자동 설정된다.