pyspark
Definition
pyspark 코드를 작성하여 실행하는 노드이다. property 패널 "3.source"에 pyspark 코드를 입력한다. Source Editor 버튼("3.source" 우측 첫 번째 버튼) 클릭 시 Editor가 팝업되며 보다 큰 화면에서 코드를 작성할 수 있다. 또한 Jupyter 사이트 바로가기("3.source" 우측 두 번째 버튼) 선택시 Jupyter Notebook이 열리며, Notebook에서 interactive하게 작업할 수 있다.
[Flow구성]노드 중 [pyspark]노드를 drag & drop 한 후 Property 항목을 입력한다. Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있다.
Set
[setting], [scheduler], [parameter] 설정은 [워크플로우 생성] > [설정]을 참고한다.
property
[Node Description] 작성 중인 노드명 입력
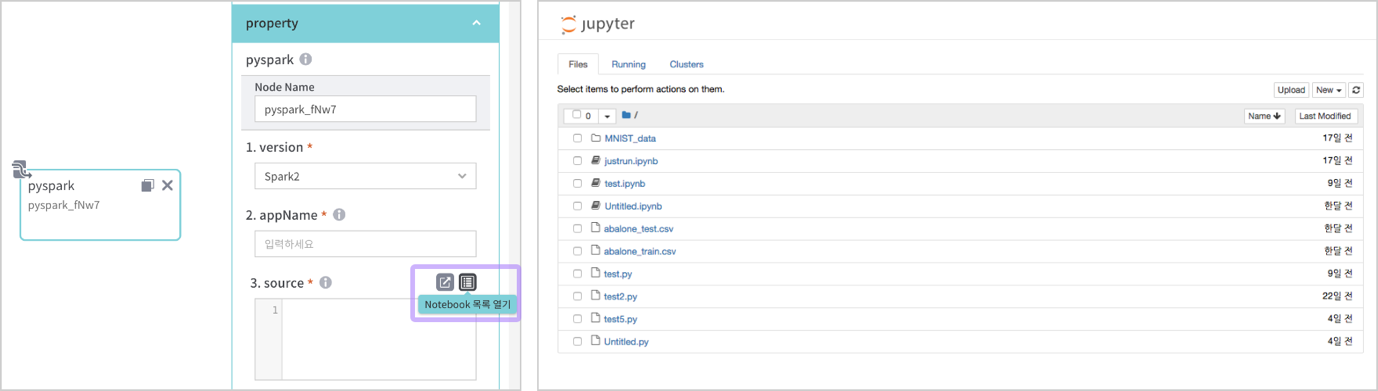
- Node_description : 작성 중인 노드명 입력
- version : spark 버전 입력(Spark2가 고정값임)
- appName : appName 입력
- source : 실행할 source code 입력
- [Source Editor]를 선택해서 팝업된 editor를 통해 코딩 가능
- [Jupyter 바로가기]를 선택해서 jupyter notebook 사용 가능
- argument : 인수 설정
- sparkOpts : 실행에 사용할 속성 (key, value) 입력
- master : spark master 입력 ( ex. yarn )
- mode : mode 입력 ( ex. client )
- forceOK : 실패 시 강제 OK 처리 여부
Example
입력받은 숫자의 평균을 구해 output.txt파일을 생성하는 예제이다.
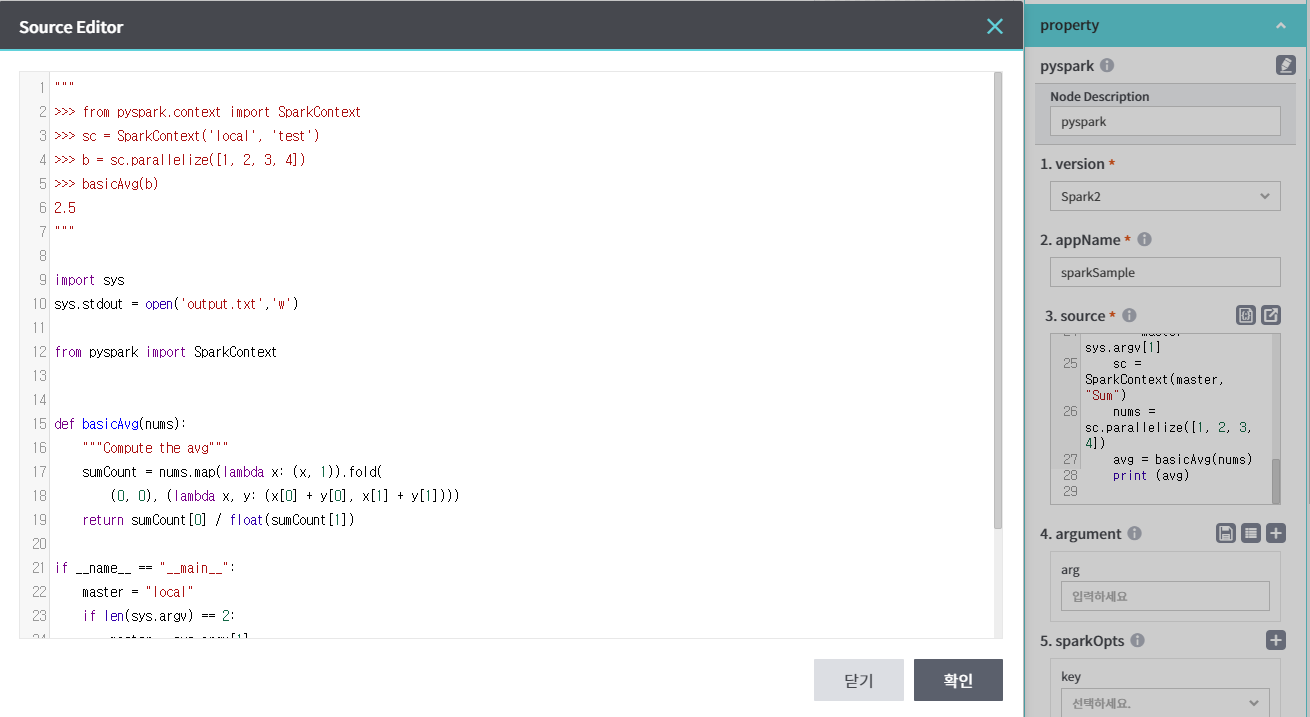
- property 패널의 3.source 옵션에 아래와 같이 입력한다.
"""
>>> from pyspark.context import SparkContext
>>> sc = SparkContext('local', 'test')
>>> b = sc.parallelize([1, 2, 3, 4])
>>> basicAvg(b)
2.5
"""
import sys
sys.stdout = open('output.txt','w')
from pyspark import SparkContext
def basicAvg(nums):
"""Compute the avg"""
sumCount = nums.map(lambda x: (x, 1)).fold(
(0, 0), (lambda x, y: (x[0] + y[0], x[1] + y[1])))
return sumCount[0] / float(sumCount[1])
if __name__ == "__main__":
master = "local"
if len(sys.argv) == 2:
master = sys.argv[1]
sc = SparkContext(master, "Sum")
nums = sc.parallelize([1, 2, 3, 4])
avg = basicAvg(nums)
print (avg)
- 워크플로우 저장/실행시 아래와 같이 output.txt파일이 생성된다.

Troubleshooting
- pyspark node 실행시 [실행할 클러스터에 주피터 노트북이 없습니다] 메시지
- pyspark node를 실행하는 클러스터에 jupyter-notebook 컨테이너가 구성되어 있는지 확인
- 워크플로우 [인스턴스 상세] > [흐름] 탭 하단의 STD 로그에 아래와 같이 에러메시지 기록됨
- java.io.IOException: Cannot run program "/usr/local/bin/python3.6": error=2, No such file or directory
- run_spark2.sh PYSPARK_PYTHON 실행경로 변경
# export PYSPARK_PYTHON=/usr/local/bin/python3.6
export PYSPARK_PYTHON=/opt/conda/bin/python3.6