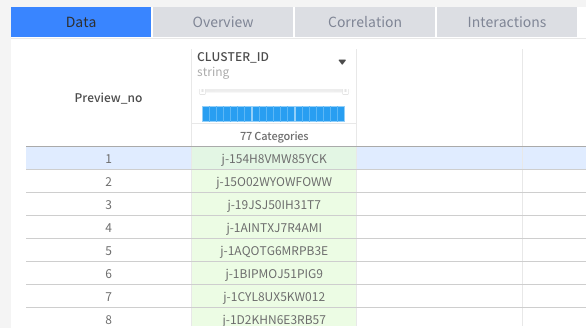
randomSplit
Definition
데이터를 비율과 seed값에 따라 두 개의 데이터로 나누는 함수 입니다.
좌측 [데이터처리(기본)]노드 중 [randomSplit]노드를 drag & drop 한 후 Property 항목을 입력합니다.
Set
[setting], [parameter] 설정은 [워크플로우] > [생성] > [기본구성]을 참고합니다.
Property
[Node Description] 작성 중인 노드명 입력
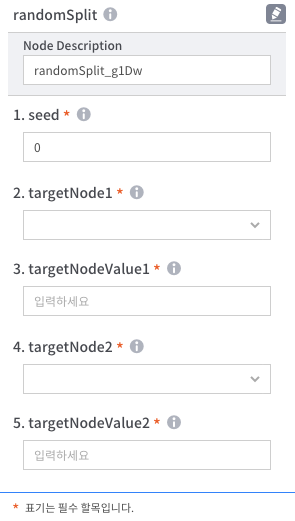
- seed : 난수 생성 프로그램의 seed
- targetNode1 : 첫 번째로 적용할 node를 선택
- targetNodeValue1 : 첫 번째로 적용 node의 weight값 입력(0~1 이내로 입력) e.g. 0.3
- targetNode2 : 두 번째로 적용할 node를 선택
- targetNodeValue2 : 두 번째로 적용 node의 weight값 입력(0~1 이내로 입력) e.g. 0.3
Example
데이터를 학습하고 테스트하기 위해 train set과 test set으로 분리를 하는 워크플로우를 작성합니다.
- [S3불러오기], [randomSplit], 그리고 원하는 2개의 데이터 처리 기본 노드를 Designer에 Drag & Drop하여 워크플로우 생성 후 연결
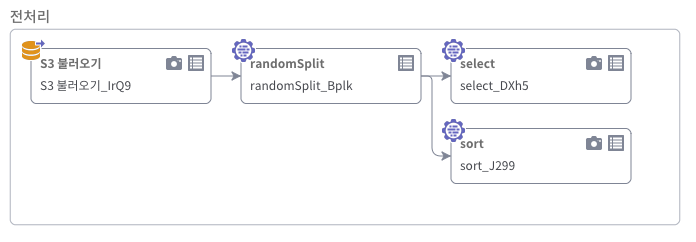
- [S3불러오기] 에서 원하는 파일을 불러온 후, randomSplit 노드를 아래 예시를 참고하여 원하는 방법으로 선택
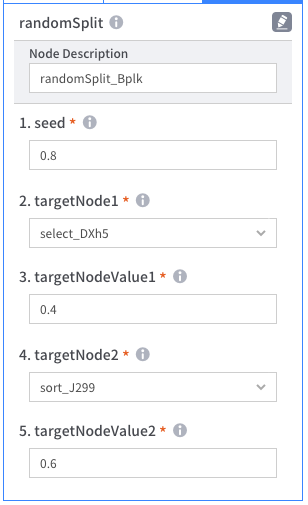
- snapshot을 확인하여 결과가 제대로 출력되는지 확인