HDFS 불러오기
Definition
HDFS에 저장된 데이터를 Pipeline으로 불러오기 위해 사용합니다.
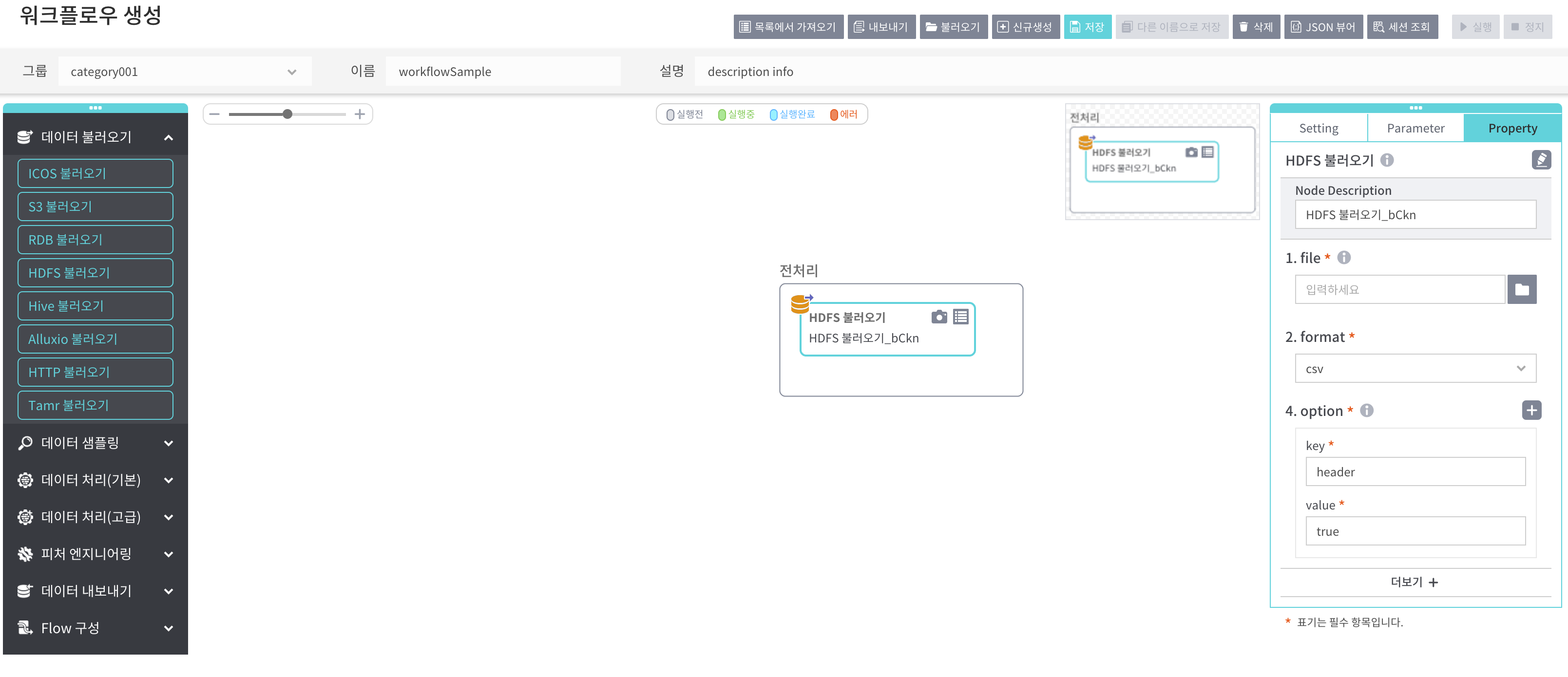
좌측 [데이터불러오기]노드 중 [HDFS불러오기]노드를 drag & drop 한 후 Property 항목을 입력합니다.
Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있습니다.
Set
[setting], [parameter] 설정은 [워크플로우] > [생성] > [기본구성]을 참고합니다.
Property
[Node Description] 작성 중인 노드명 입력
file : File 브라우저에서 불러올 hdfs 파일 경로 입력(직접 IP/경로를 입력하거나 브라우저를 열어서 선택)
format : 불러올 파일의 형식 지정(json, parquet, orc, csv, text 중 택1)
delimiter : 구분자 입력
option : 사용 가능한 옵션(헤더유무, nanValue, nullValue) 설정(key, value형식 입력)
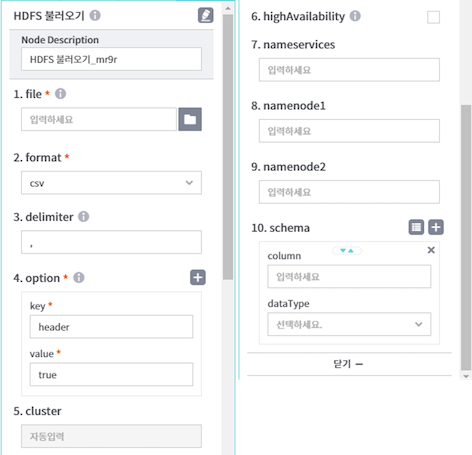
key value 설명 header true / false true : 헤더 설정, false : 헤더 미설정 nullValue 입력값(ex:NULL) 데이터에 포함된 입력값(NULL)을 Null문자열 처리 nanValue 입력값((ex:NaN)) 데이터에 포함된 입력값(NaN)을 NaN문자열 처리 cluster : 자동입력됨
hightAvailability : 고가용성 사용 여부 체크(7,8,9 에서 상세 정보 입력)
nameservices : 고가용성 호스트 명 입력
namenode1 : 호스트 명을 통해 접속할 실제 이중화 IP 입력
namenode2 : 호스트 명을 통해 접속할 실제 이중화 IP 입력
schema : column 및 dataType 정의(우측 [자동파싱], [추가]버튼 활용. 파싱을 완료해야 이후 연결할 노드에서 사용가능)
- [자동파싱] : 불러올 데이터 유형(숫자형, 문자형)에 맞게 pipeline에서 자동 파싱. 사용자가 dataType 변경 가능
- [추가] : 사용자가 데이터 column, dataType을 직접 파싱
property탭의 option 처리방법
아래는 nullValue, nanValue를 처리하는 방법에 대해 설명합니다.
nullValue 처리
HDFS에서 불러오는 데이터에 "NULL"이라는 문자열이 있을 경우, 이를 null로 볼 것인지 설정하는 옵션입니다. HIVE의 경우 null 데이터가 "NULL"이라는 문자로 표기되며, 데이터 추출시 default로 "NULL"이란 문자가 저장되므로 이를 실제 null 값으로 변환하는 작업이 필요합니다.
실제 null 값인데 "NULL"이란 문자열로 입력됨
Property 탭의 4.option에서 [+] 버튼 클릭 후 아래와 같이 key, value 설정
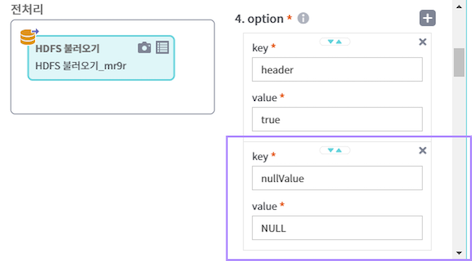
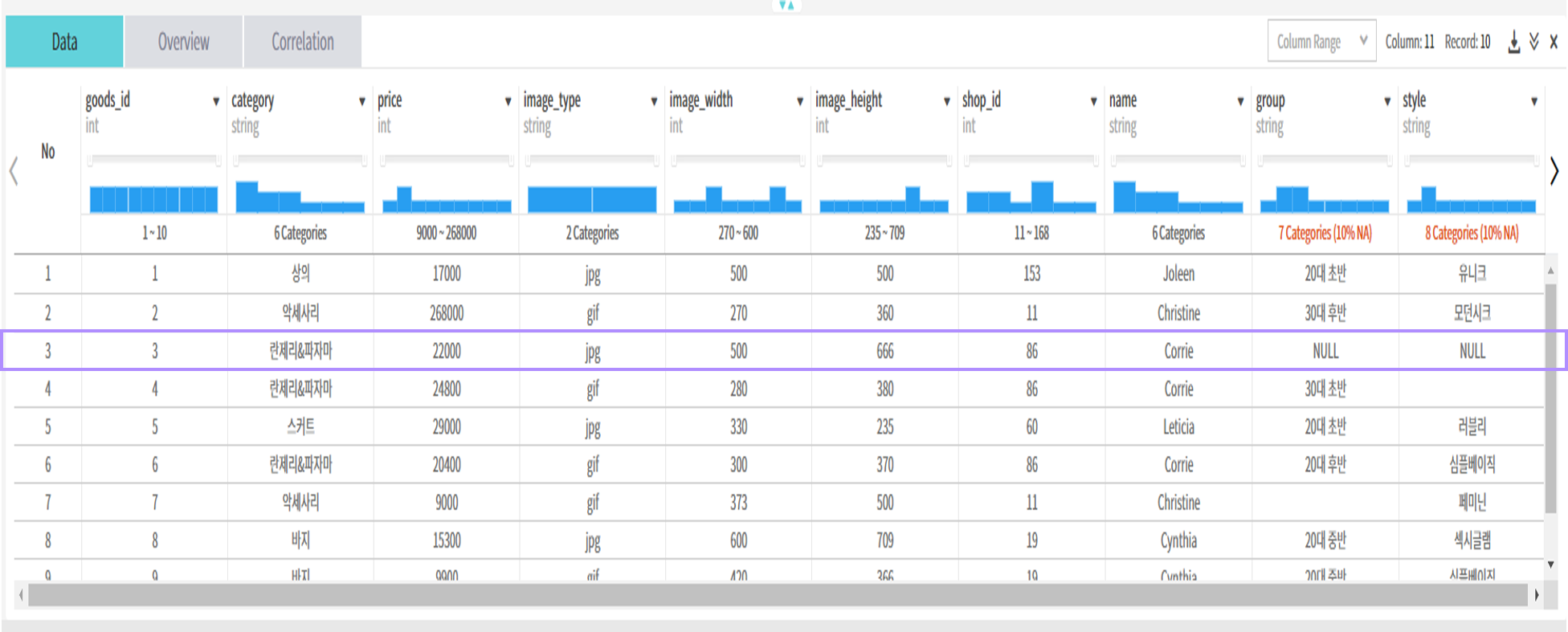
nullValue 설정 결과는 다음과 같음
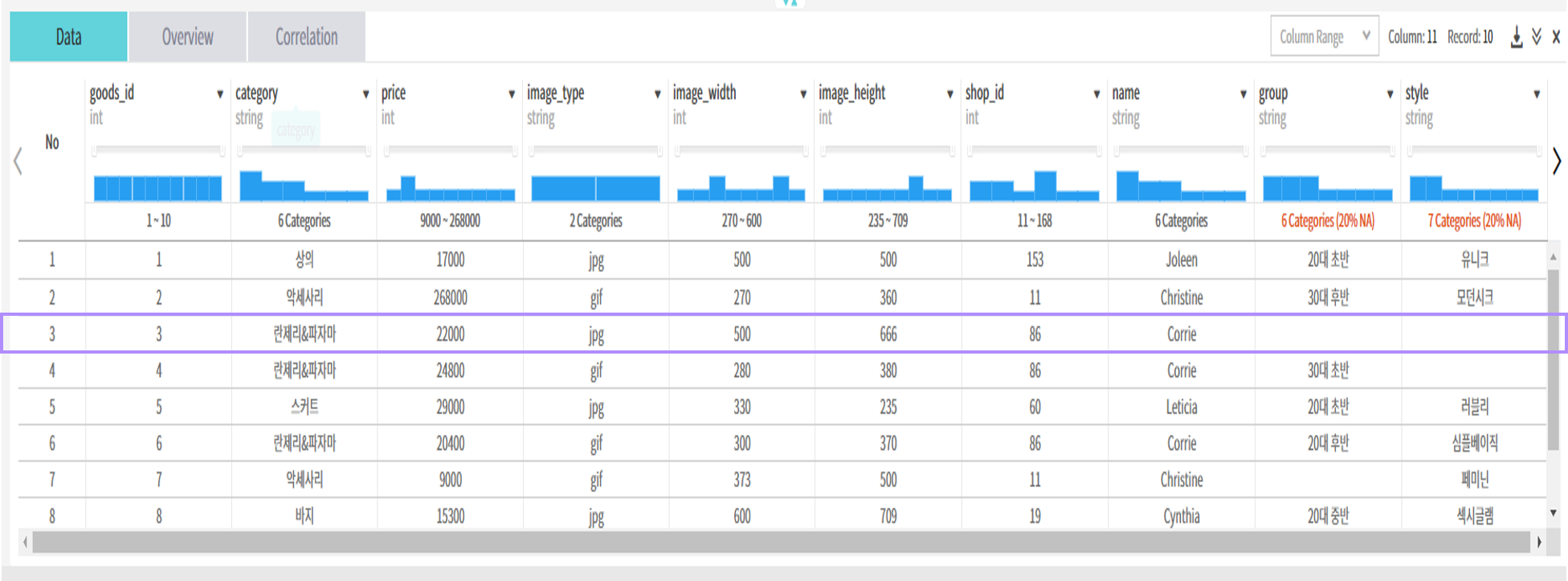
nanValue 처리
HDFS에서 불러오는 데이터를 숫자 타입으로 파싱하고 싶은데 "NAN"과 같은 문자열이 입력되어 있을 경우 문자열컬럼으로 인식됩니다. 이럴 경우 문자열을 NaN(Not a Number)이란 키워드로 대체한 후 숫자타입 필드로 변경할 수 있습니다.
"NAN"이란 문자열이 입력되어 자동파싱 결과 String type으로 매핑됨
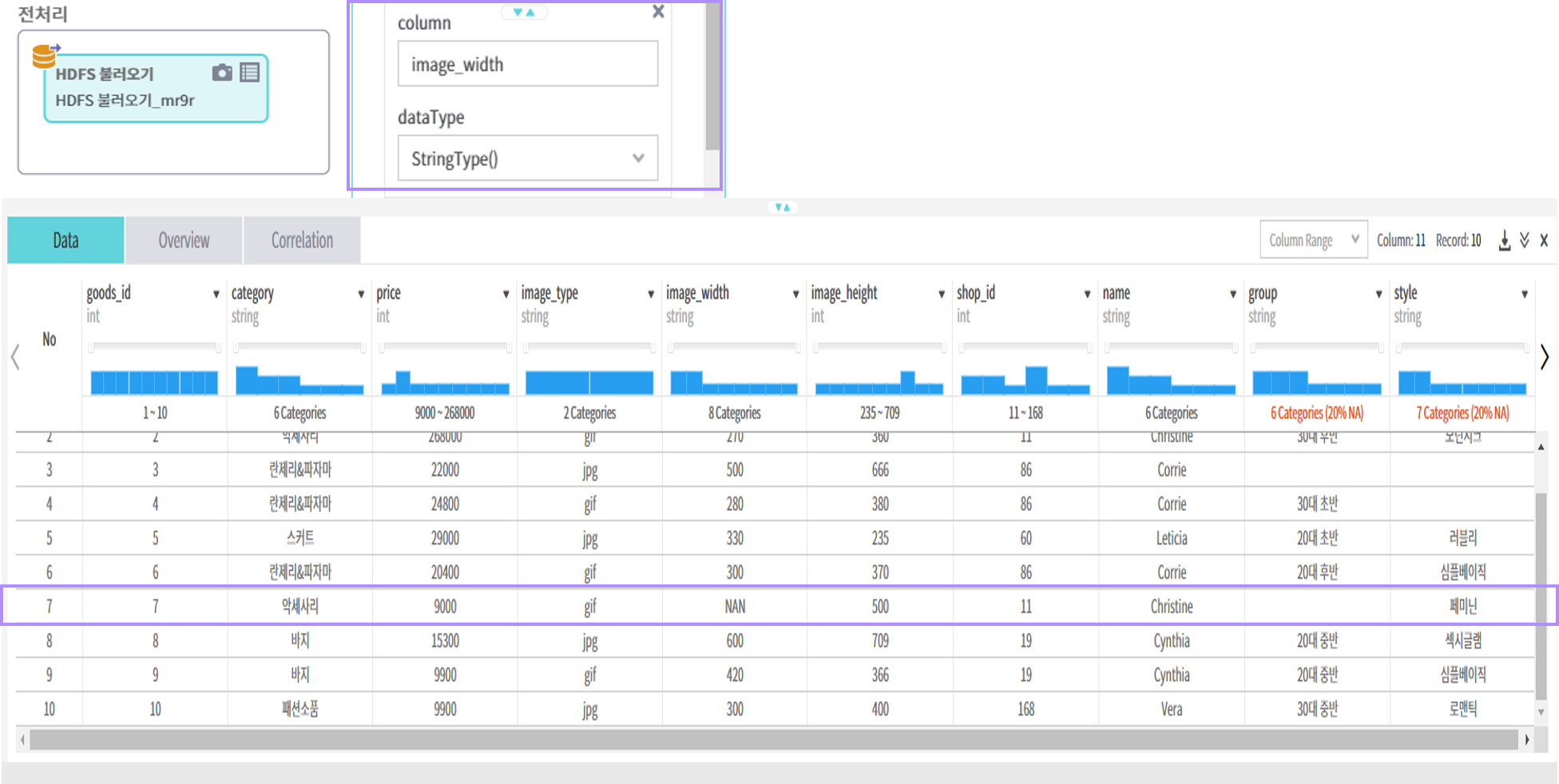
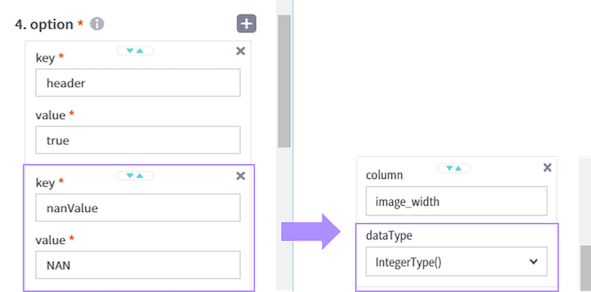
property 탭 4.option에서 [+] 버튼 클릭하여 key, value 설정 후 11.schema에서 image_width 컬럼을 IntegerType()으로 변환
nanValue설정결과는 다음과 같음(NAN값이 입력된 레코드가 삭제되고, image_width컬럼은 InterType으로 변경)