mlPredict
Definition
기 저장된 모델을 이용하여 ml 학습을 실행하는 노드입니다.
좌측 [Flow구성]노드 중 [mlPredict]노드를 drag & drop 한 후 Property 항목을 입력합니다.
Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있습니다.
Set
[setting], [scheduler], [parameter] 설정은 [워크플로우] > [생성] > [기본구성]을 참고합니다.
property
[Node Description] 작성 중인 노드명 입력
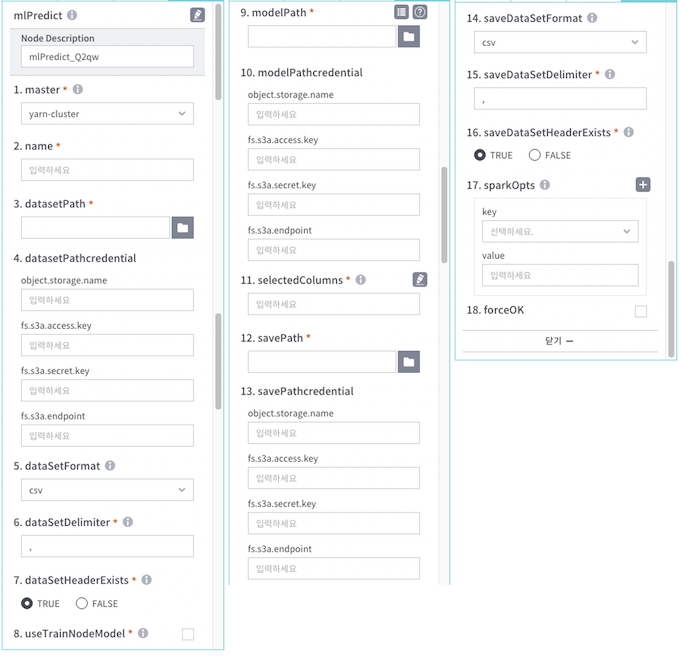
- master : ml 실행할 master 선택 (yarn-cluster, yarn-client, local 중 선택)
- name : appName 입력
- datasetPath : ml predict을 수행할 데이터셋 경로
- datasetPathcredential : datasetPath가 s3인 경우 credential 정보
- dataSetFormat : 데이터셋 포맷 선택 (parquet, csv, orc 중 선택)
- dataSetDelimiter : 데이터셋 구분자 입력
- dataSetHeaderExists : 데이터넷 header가 있는지 여부 (TRUE, FALSE 중 선택)
- useTrainNodeModel : 연결된 mlTrain 노드의 학습결과 모델 사용 여부
- modelPath : 모델 경로
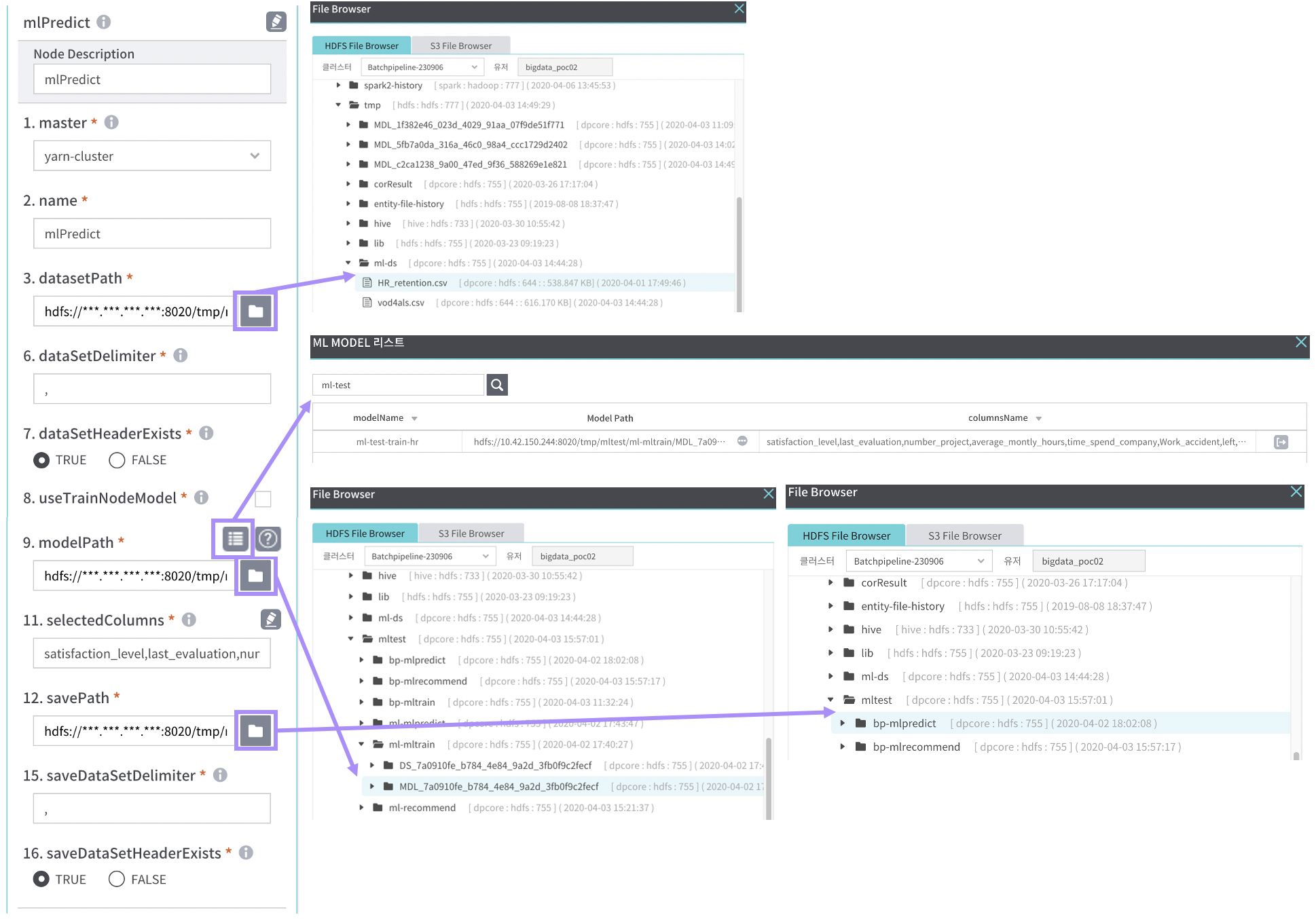
- 팝업열기 : HDFS, S3 File browser 팝업에서 모델 경로를 선택
- ml model 불러오기 : 기존에 등록된 model을 선택
- ml 정보보기
- modelPathcredential : modelPath가 s3인 경우 credential 정보
- selectedColumns : 가져올 컬럼 선택 (Dataset(결과)스키마 불러오기 버튼으로 불러오거나 직접 입력 가능)
- savePath : 저장할 경로 선택
- savePathcredential : savePath가 s3인 경우 credential 정보
- saveDataSetFormat : 저장할 데이터셋 포맷 선택 (parquet, csv, orc 중 선택)
- saveDataSetDelimiter : 저장할 데이터셋 구분자 입력
- saveDataSetHeaderExists : 저장할 데이터셋 header가 있는지 여부 (TRUE, FALSE 중 선택)
- sparkOpts : spark 옵션 리스트 입력 (ex. key : --executor-memory , value : 20G)
- forceOK : 실패 시 강제 OK 처리 여부
Example
Property
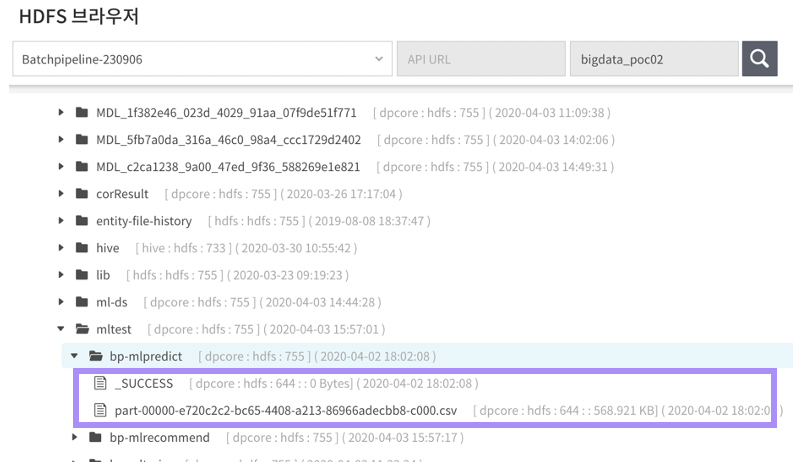
Dataset과 모델, 결과 저장 위치를 HDFS 브라우저로 사용하는 예시입니다.
실행 결과
[브라우저] > [HDFS] 브라우저에서 mlPredict 실행 결과로 저장된 데이터셋을 확인 할 수 있습니다.