SnowFlake 불러오기
Definition
snowFlake에 저장된 데이터를 Pipeline으로 불러오기 위해 사용합니다.
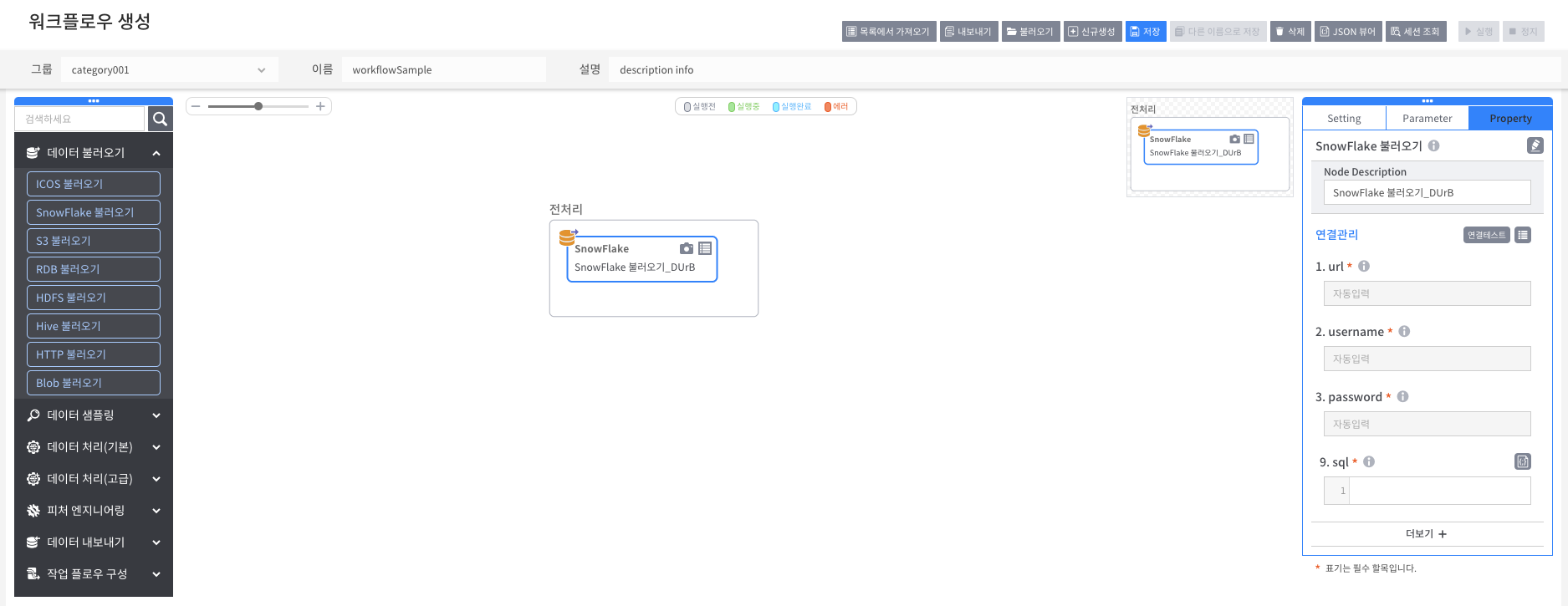
좌측 [데이터불러오기]노드 중 [RDB불러오기]노드를 drag & drop 한 후 Property 항목을 입력합니다.
Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있습니다.
Set
[setting], [parameter] 설정은 [워크플로우] > [생성] > [기본구성]을 참고합니다.
Property
[Node Description] 작성 중인 노드명 입력
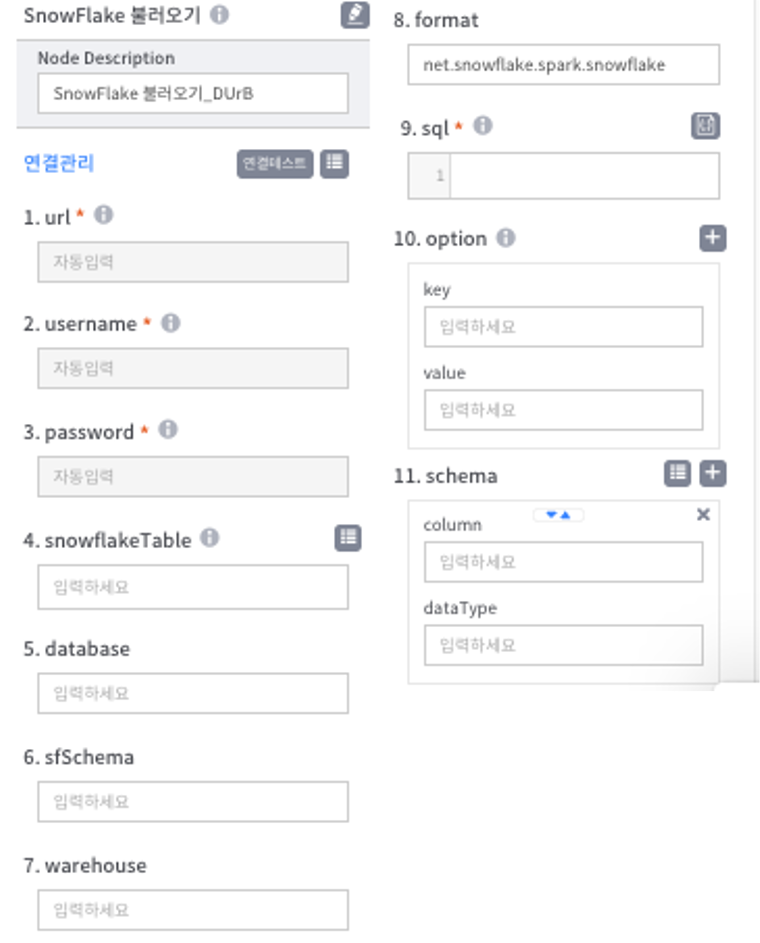
- url : JDBC 접속 URL. 1~4 입력항목은 [연결관리]에서 선택한 정보를 자동으로 조회함(직접 입력할 수 없음)
- username : database 사용 계정
- password : 패스워드
- snowflakeTable : 데이터베이스 스키마에서 생성되고 유지되는 기본 오브젝트
- database : 스키마를 논리적으로 그룹화한 것
- sfSchema : 데이터베이스 오브젝트(테이블, 뷰 등)를 논리적으로 그룹화한 것
- warehouse : Snowflake의 컴퓨팅 리소스 클러스터입니다. 웨어하우스는 Snowflake 세션에서 다음 작업을 수행하기 위해 필요한 리소스(예: CPU, 메모리 및 임시 저장소)를 제공합니다.
- format : Spark에서 Snowflake를 데이터 소스로 사용하려면 .format 옵션을 사용하여 데이터 소스를 정의하는 Snowflake 커넥터 클래스 이름을 제공합니다.
- sql : SQL 입력(우측 [Query Editor] 버튼 클릭시 SQL 편집기 팝어되어, 보다 큰 화면에서 SQL 입력가능)
- option : 사용 가능한 옵션설정(헤더유무, nanValue, nullValue) 설정
- key: header, value : true/False = 헤더 설정 여부(True : 헤더설정, False : 헤더미설정)
- key: nullValue, value : 입력값(ex:NULL) = 데이터에 포함된 입력값(NULL)을 Null문자열 처리
- key: nanValue, value : 입력값(ex:NaN) = 데이터에 포함된 입력값(NaN)을 NaN문자열 처리
- schema : column 및 dataType 정의(우측 [자동파싱], [추가]버튼 활용. 파싱을 완료해야 이후 연결할 노드에서 사용가능)
- [자동파싱] : 불러올 데이터 유형(숫자형, 문자형)에 맞게 pipeline에서 자동 파싱. 사용자가 dataType 변경 가능
- [추가] : 사용자가 데이터 column, dataType을 직접 파싱. schema 상세활용법은 [HDFS불러오기] 참고
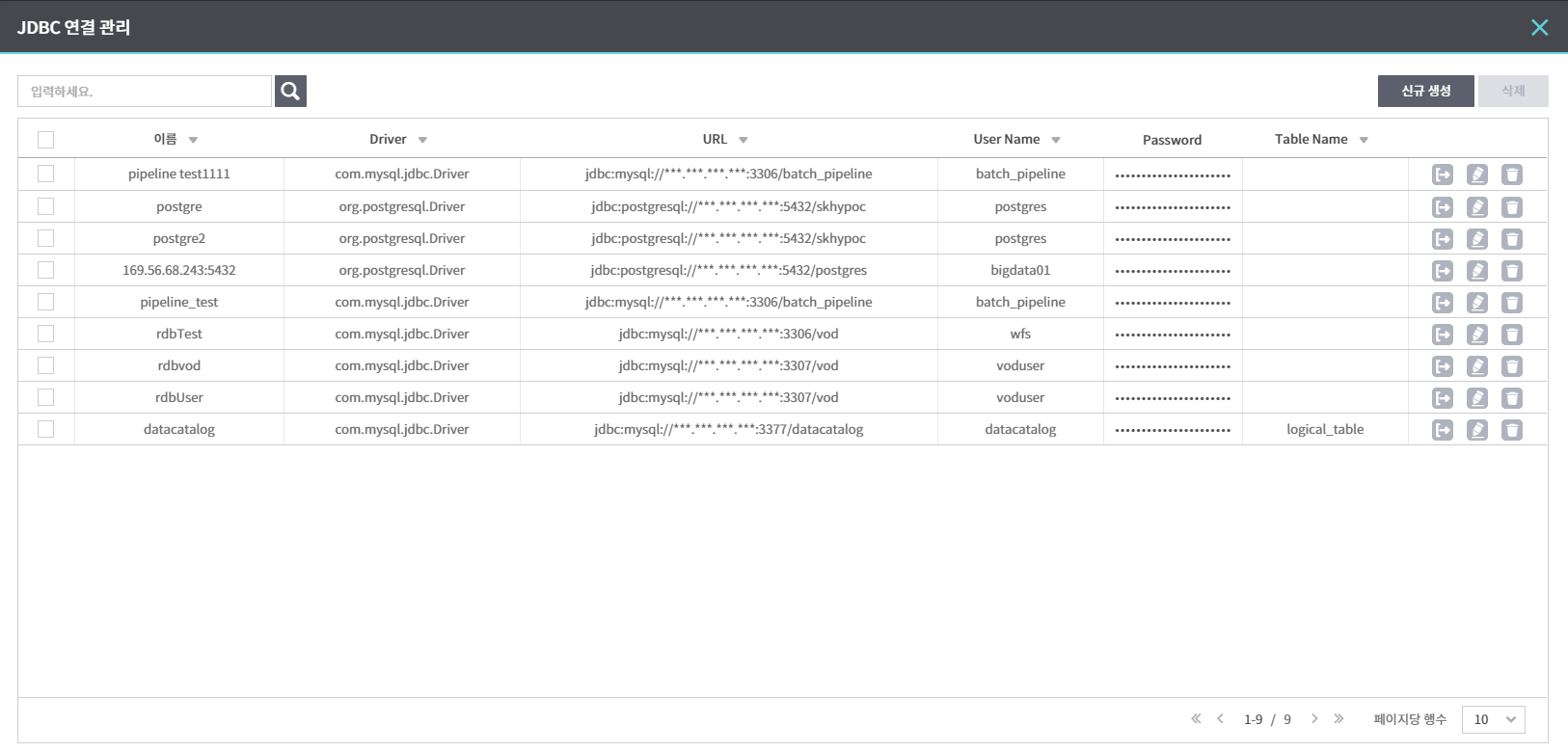
JDBC 연결관리
[snowFlake불러오기]에서 사용하기 위한 JDBC접속정보는 [설정] > [JDBC연결관리]에 저장된 정보를 불러와서 사용(Property탭에서 직접 입력 불가)합니다. [연결관리] 우측의 2개 버튼 사용방법은 아래와 같습니다.
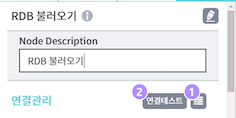
- 목록열기 : [설정] > [JDBC연결관리]에서 입력한 JDBC접속정보 목록 조회/선택
- 연결테스트 : JDBC접속테스트 수행
목록열기
[목록열기] 버튼 선택하여 기저장된 RDB목록을 적용할 수 있으며, [목록열기]로 팝업된 [JDBC 연결 관리] 창의 [신규생성] 버튼을 활용해서 RDB 접속정보를 입력할 수 있습니다. 신규생성방법은 [JDBC연결관리] 내용을 참고합니다.
연결테스트
[목록열기]에서 선택한 JDBC접속정보가 정확한지 [연결테스트]를 통해 확인할 수 있습니다. 연결테스트가 실패할 경우 JDBC접속정보가 잘 못 설정되었는지, dbms 서비스에 문제가 있는지 등을 점검합니다.