random
[데이터샘플링]에 있는 노드는 [데이터불러오기]에서 불러온 전체 데이터 중 일부 값을 추출하기 위해 사용합니다. Pipeline에서는 random, systematic, stratified, cluster 등 총 4개의 샘플링기법을 제공합니다.
Definition
[데이터불러오기]에서 불러온 데이터를 모두 동등한 확률로 샘플링할 때 사용합니다.
좌측 [데이터샘플링]노드 중 [random]노드를 drag & drop 한 후 Property 항목을 입력합니다.
Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있습니다.
Set
[setting], [parameter] 설정은 [워크플로우] > [생성] > [기본구성]을 참고합니다.
Property
[Node Description] 작성 중인 노드명 입력
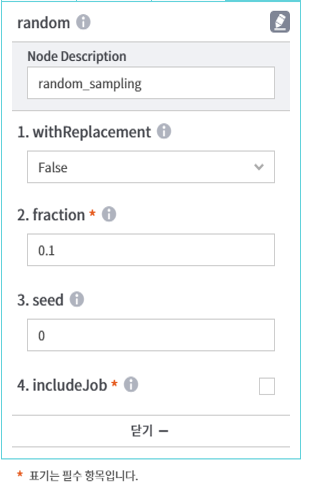
[Node Description] 작성 중인 노드명 입력
- withReplacement : 복원 추출 여부 선택
- true : 복원추출(한 번 추출한 데이터를 복원하여 다시 할 수 있음)
- False : 비복원추출(추출한 데이터는 제외하고 sampling 수행)
- fraction : 리턴할 데이터셋과 전체 데이터셋 간의 크기 비율을 의미하며, 0~1사이의 값 입력
- seed : 랜덤 추출 seed 값(컴퓨터가 난수를 일정하게 생성하지 않도록 변화를 주는 값) 입력
- includeJob : 배치/스케줄링 작업 수행 시 샘플링 포함여부
Example
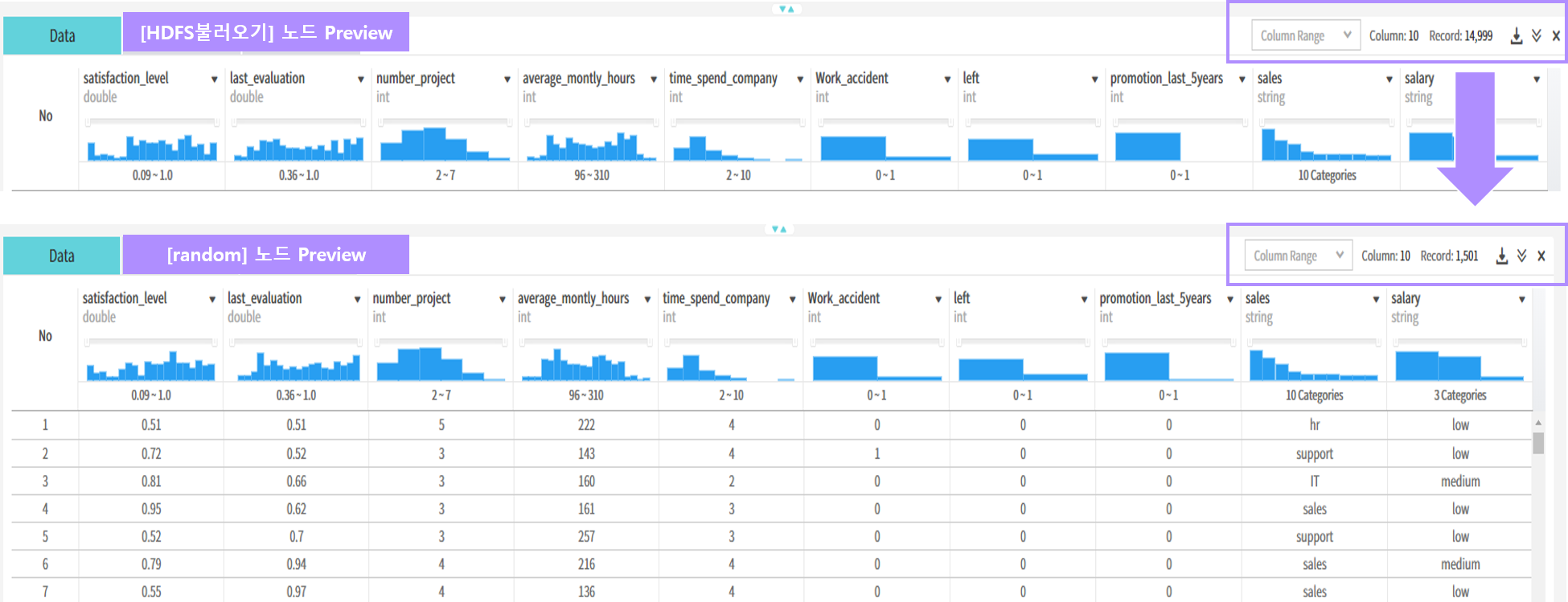
HDFS에 등록된 데이터(HR_Retention.csv, 10 cloumns/14,999 records)를 비복원추출 방식(withReplacement=false)으로 샘플링하는 예시입니다.
- [HDFS불러오기], [random] 노드를 Designer에 Drag & Drop하여 워크플로우 생성
- [random]노드의 fraction 값을 0.1로 설정(전체 데이터 중 10%만 샘플링)
- [random]노드의 snapshot을 클릭하면 아래와 같이 10%가량의 데이터(14,999 > 1,501)가 샘플링됨을 확인가능
[Note] 복원 추출(sampling with replacement)
복원추출이란 확률을 구할 때, 추출했던 것을 원래대로 돌려놓고 다시 추출하는 방법을 말한다. 예를 들어 바구니 안에 숫자카드 1, 2, 3이 모두 한 개씩 들어 있다. 이때 표본크기 2로 복원 추출을 해서 나올 수 있는 가짓수는 (1,1) (1,2) (1,3) (2,1) (2,2) (2,3) (3,1) (3,2) (3,3) 총 9가지이다.
반대로 비복원추출은 추출했던 것을 원래대로 돌려놓지 않고 다시 추출하는 방법이다.
출처 : https://www.scienceall.com/%EB%B3%B5%EC%9B%90-%EC%B6%94%EC%B6%9Csampling-with-replacement/