HDFS 내보내기
Definition
워크플로우 실행 결과를 hdfs에 저장하기 위해 사용합니다.
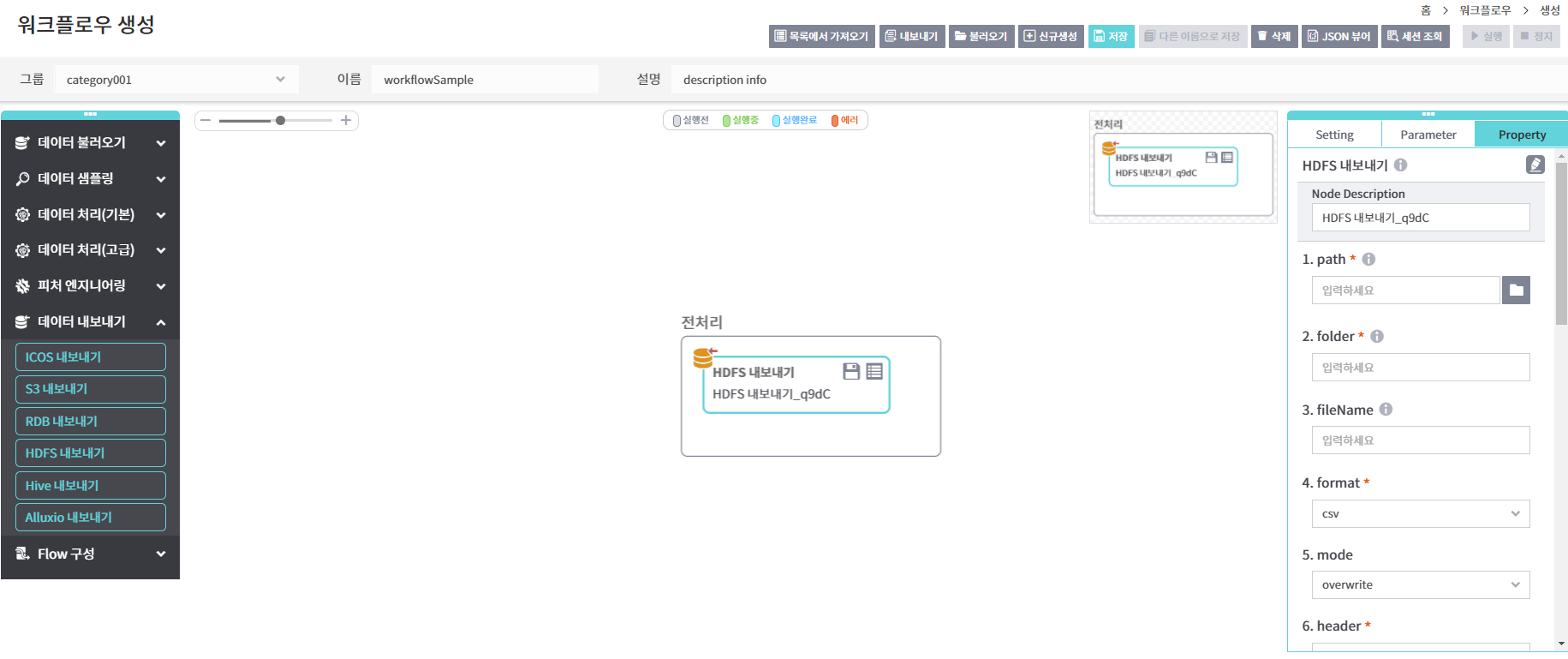
좌측 [데이터내보내기]노드 중 [HDFS내보내기]노드를 drag & drop 한 후 Property 항목을 입력합니다.
Property 패널의 [더보기+] 버튼을 누르면 입력가능한 전체 Property 항목을 볼 수 있습니다.
Set
[setting], [parameter] 설정은 [워크플로우] > [생성] > [기본구성]을 참고합니다.
Property
[Node Description] 작성 중인 노드명 입력
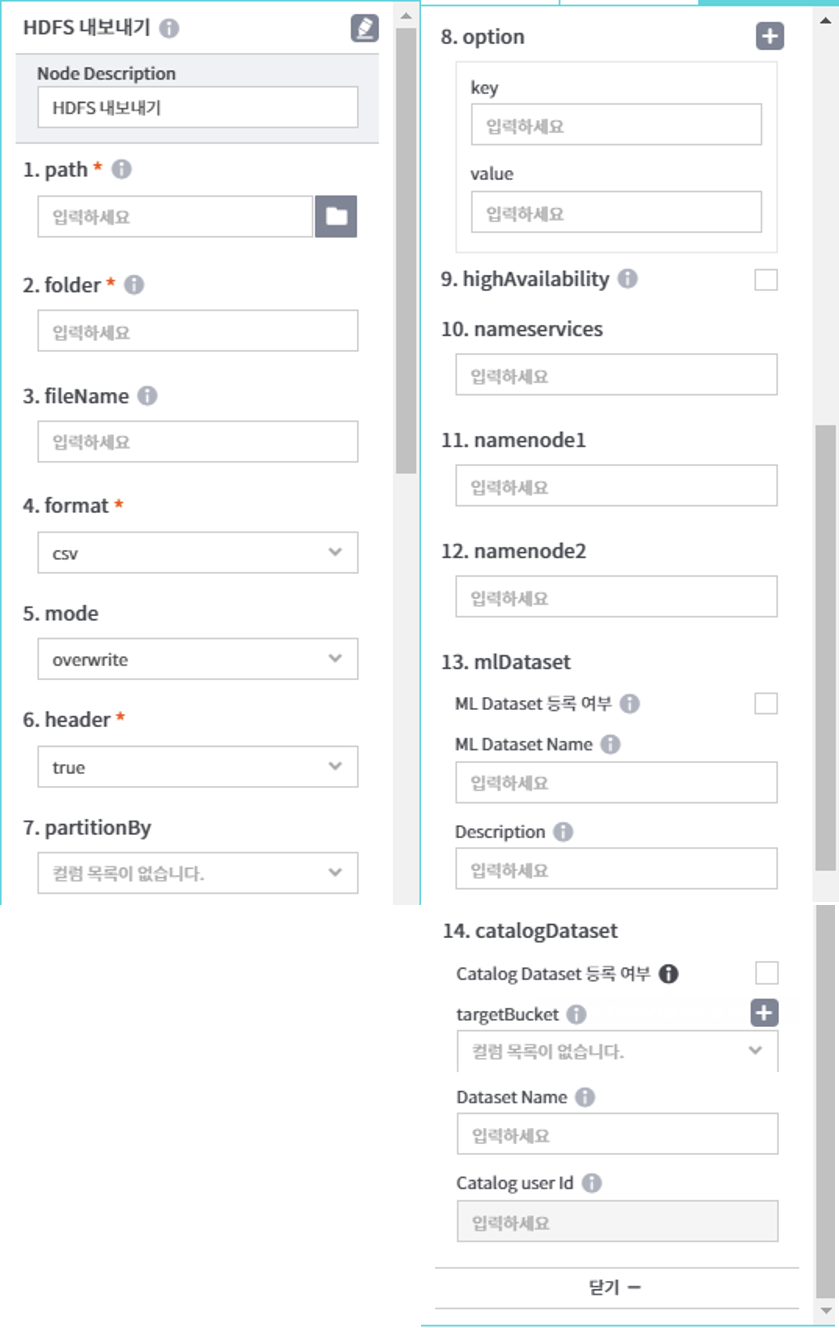
path : 데이터 저장 경로 설정
folder : 데이터 저장 폴더명. 날짜 표현식 입력하여 해당 날짜로 치환 가능하며, 관련 Guide는 아래와 같음
날짜 표현식 : #{now:날짜 포맷}
현재 날짜가 2019년 7월 3일 12시인 경우 아래와 같이 표현 가능
/test/#{now:yyyyMMdd} 로 지정시 /test/20190703 이란 디렉토리로 치환됨
표현식 설명 #{now:yyyyMMdd} 오늘 날짜 20190703 으로 치환 #{now-1d:yyyy-MM-dd} 어제 날짜 2019-07-02로 치환 #{now-1w:yyyyMMddHH} 1주일전 날짜 2019062612로 치환
filename : Hadoop 처리 결과파일(기본파일명 : part-*)을 지정된 이름으로 변경
format : 저장 포맷 설정(json, orc, parquet, csv, text 중 택1)
mode : 저장모드 설정
- error : 파일이 있으면 에러 처리
- append : 다른 이름으로 파일 추가
- overwrite : 기존 파일을 삭제하고 추가
- ignore : 파일이 있으면 저장하지 않고, 에러 처리도 하지 않음
header : 헤더 여부(true, false 중 택1)
partitionBy : 특정 컬럼에 대해 Partitioning 하여 데이터 저장가능(컬럼 데이터별로 하위 폴더가 생성)
option : key, value 설정(null을 문자열로 인식하는 것을 방지 할 수 있음)
highAvailability : 네임노드의 HA구성 여부 결정
nameservices : nameNode 명 기재
namenode1 : 이중화 nameNode 의 첫번째IP
namenode2 : 이중화 nameNode 의 두번째IP
mlDataset
- ML Dataset 등록여부 : ML Dataset을 등록할 경우 체크
- ML Dataset Name : ML Dataset 명 입력
- Description : ML Dataset 상세설명 입력
catalogDataset
- Catalog Dataset 등록여부 : Catalog Dataset을 등록할 경우 체크
- targetBucket : Catalog Bucket 지정
- Dataset Name : Catalog Dataset 명 입력
- Catalog user id : Catalog user id 입력
Example
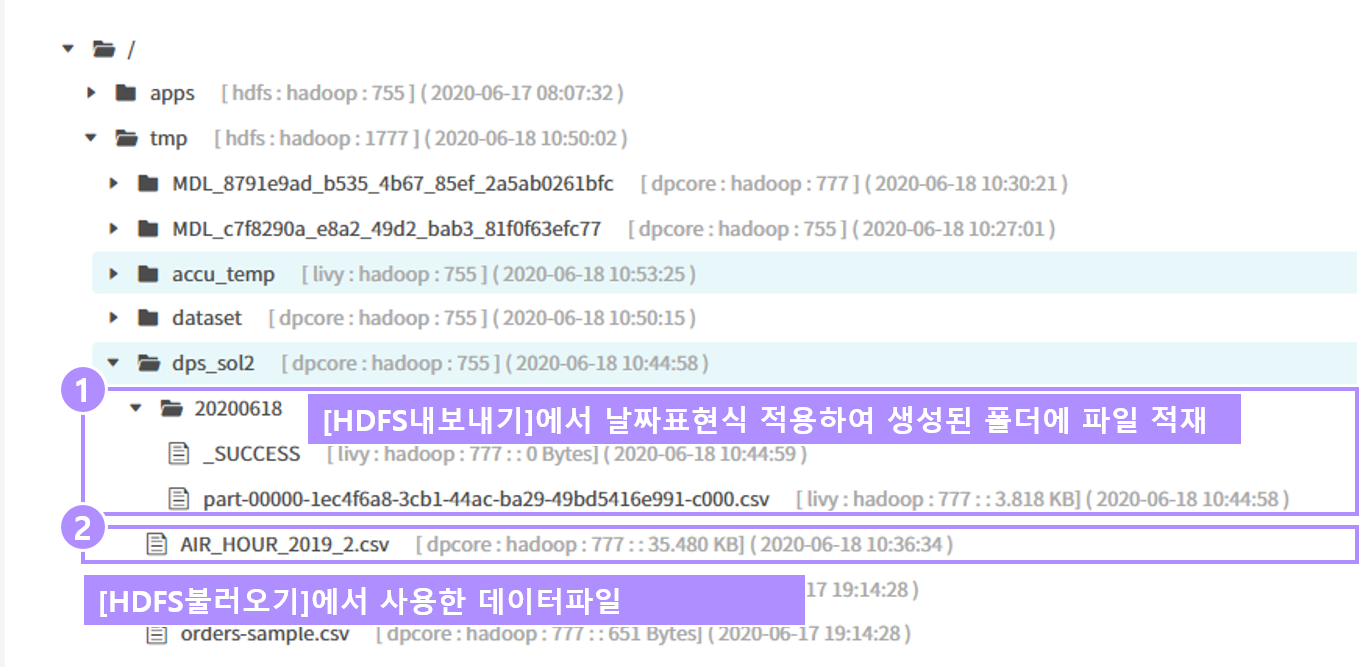
Sandbox에 적재된 서울특별시 대기오염 측정정보(2019년기준, 출처 : 공공데이터포털, https://www.data.go.kr)를 sampling 하여 이를 다시 hdfs에 저장합니다. 저장폴더에는 날짜표현식을 적용합니다.
- [HDFS불러오기], [random], [HDFS내보내기] 노드를 Designer에 Drag & Drop하여 워크플로우 생성

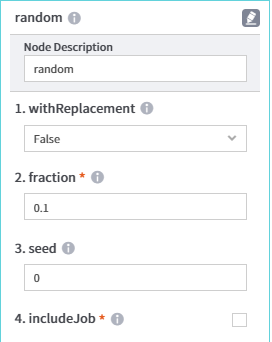
- [random]노드에서 비복원방식으로 10%만 추출(fraction 값을 0.1)하도록 설정
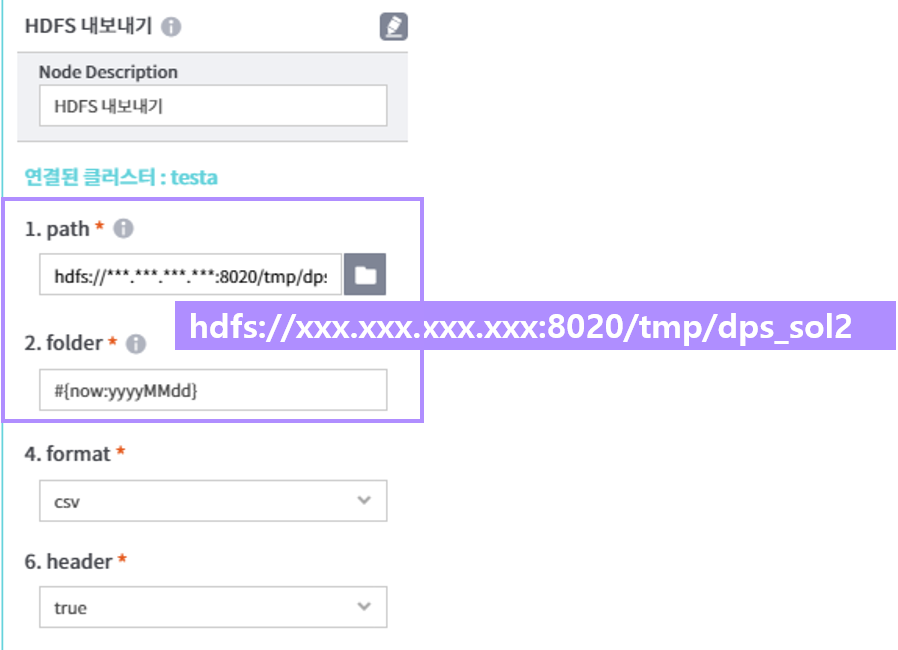
- [HDFS내보내기]노드에 아래와 같이 입력 후 추출데이터 확인
- [브라우저] 메뉴에서 추출된 데이터 확인가능
- [ML 데이터셋 등록] hdfs내보내기 노드에서
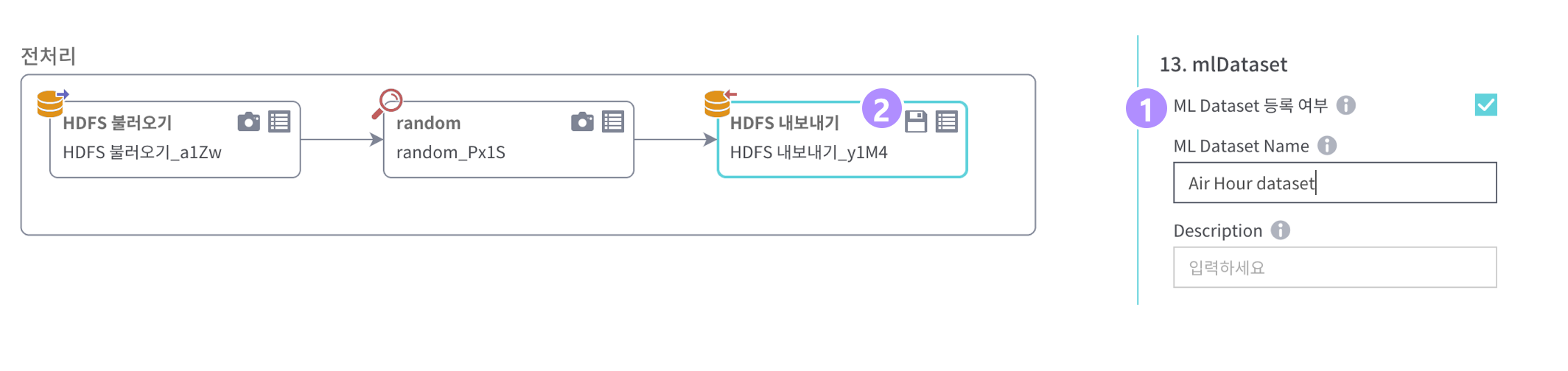
- mlDataset 정보를 입력 및 체크박스 클릭
- 저장버튼으로 등록처리 후 확인
